"Community: Graphical Modelling and Causal Inference"
{kind=link}

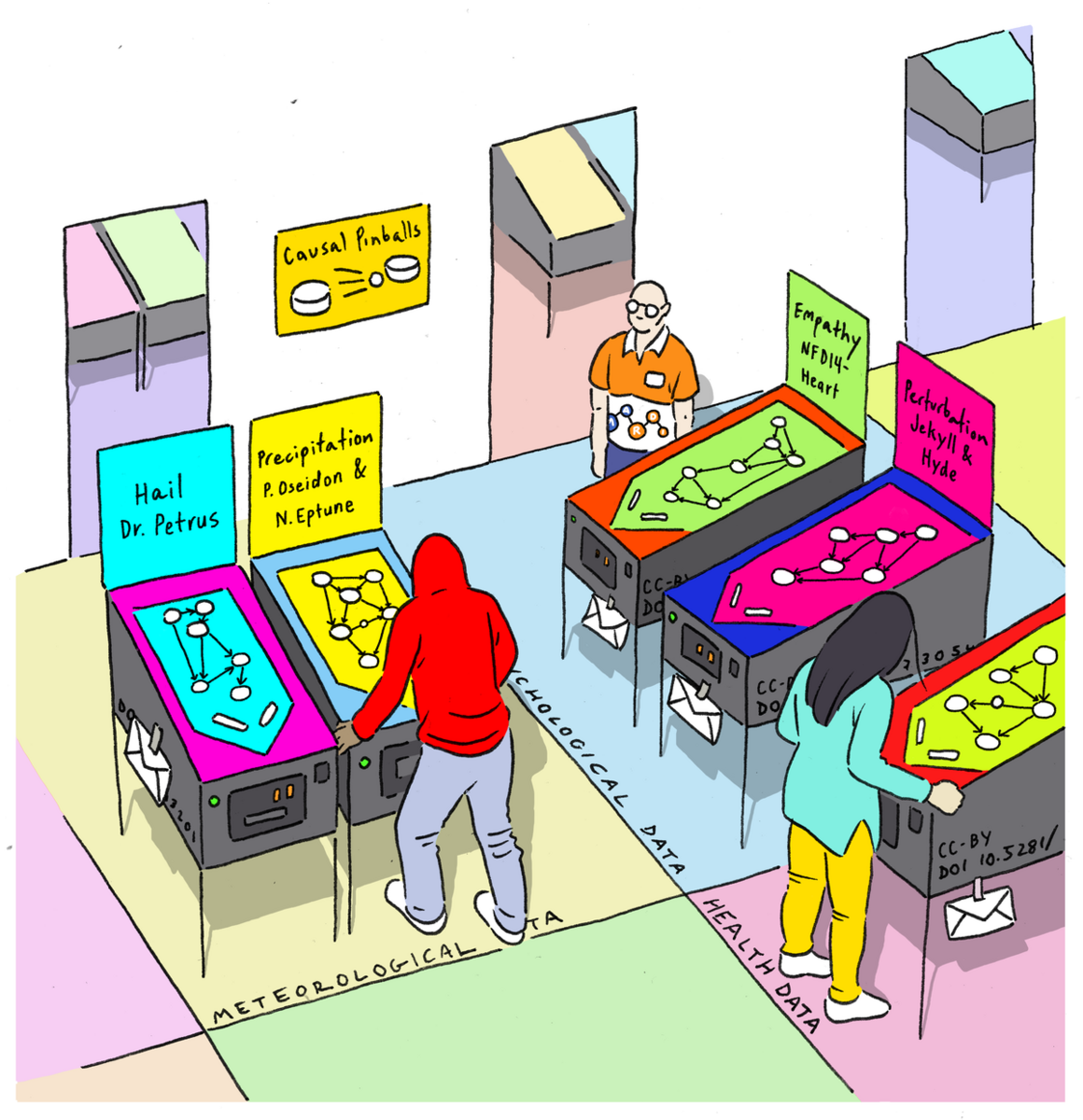
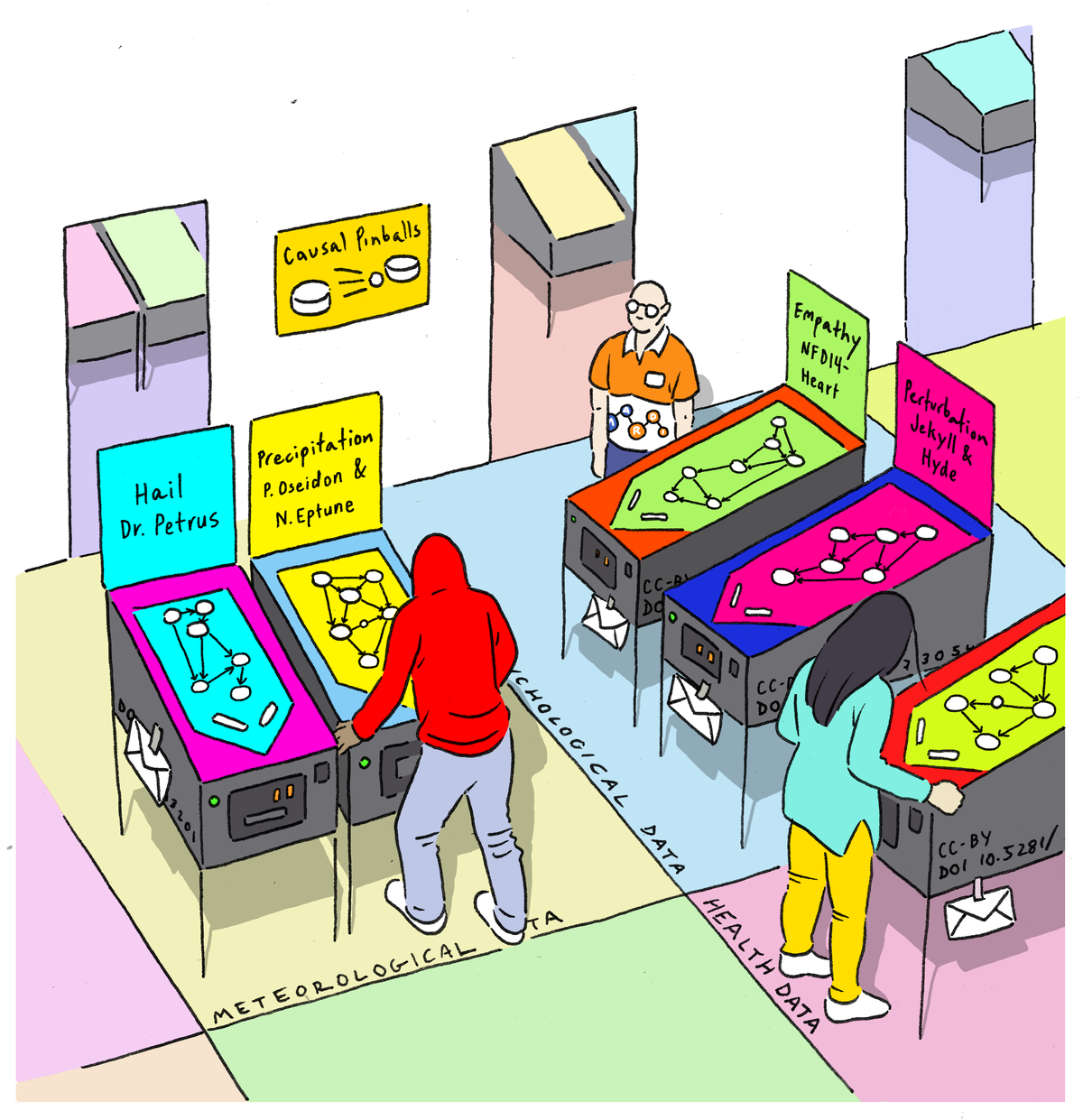
Four short stories on graphical modelling and causal inference
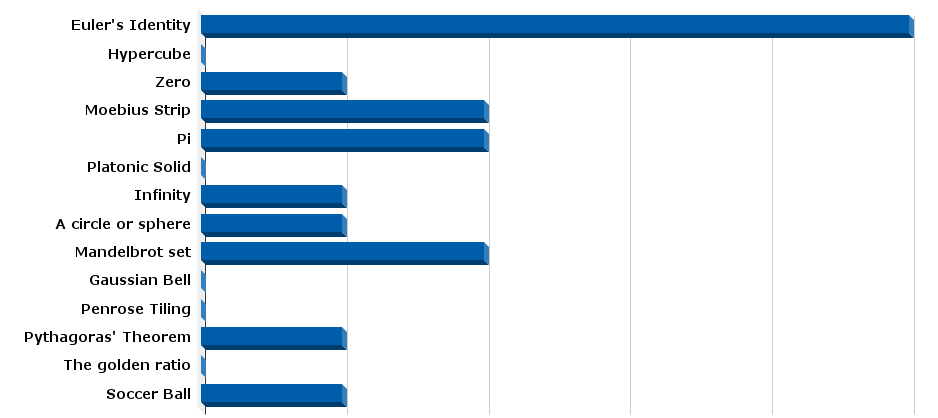
Causality is the science of "why", analyzing cause-and-effect relationships. Why is there a MaRDI community for graphical modelling and causal inference? Just because it was needed.
Find out the basics and more details in our short stories.
1. Getting started in the field of causal inference
Johan just started working in a clinical research laboratory. He has a background in biomedicine, and his supervisor, Dr. Naucki, is training him on new protocols she is implementing to measure the efficacy of drugs and treatments. On their first conversation about Johan’s future job, he was somehow astonished to learn that most of his knowledge about descriptive statistics, including correlation tests, was just part of the tools to answer questions such as “why does a drug improve a certain health condition?”
“So, which statistical tests do we use in this study? Linear regression? Chi-square test? Fitting distributions?” asked Johan. “Well, these are correlation tests, but you know, correlation does not mean causation. We will do a causal study. Have you ever done such a thing?” replied Dr. Naucki. “Hmm, no. How can you test causality if not by observing correlation?”
“There is a whole field of study called causal inference,” she continued. “The idea is that observing data alone cannot tell you whether a correlation between two variables is the result of a cause-and-effect mechanism, or which one is the cause and which the effect, or if it is just a spurious coincidence, or if both correlated variables are the effect of a third variable you haven’t discovered yet, or other more complex structures. An effect is a result of an action, so you need information about the actions that were performed in your data, not just observation of results. The proper way of describing a cause-and-effect relationship is to create a graph, on which your nodes are your variables, and your directed edges are causal relationships. Then you apply statistical tests based on that graph.”
“Hm, how does that graph differ from establishing correlations?” inquired Johan, to which Dr. Naucki explained with an example: “Well, take, for instance, a database of locations and temperatures. You may observe that altitude and temperature are correlated. But the causal relationship is from altitude to temperature, not the other way around. If you increase the altitude of your probe (e.g., by raising it on a helium balloon), you will get colder temperatures. But if you make your probe colder (e.g., by putting it into a freezer), you will not magically move it to a higher place. So you can create a graph in which you have the altitude and temperature as nodes, and the directed arrow from the first to the second. Of course, there are many other variables that affect the temperature, so most often you only have a partial view of all the causes and effects at play.”
Johan was getting the point now. “Well, and how do you create such a graph just from the data, if you have no known physical law backing you? And once you have it, how do you use it to make predictions or choices, such as whether a drug is helpful to treat a sickness?” he asked. “These are precisely the two main questions to answer in causal discovery and causal inference. Different techniques are used, but one key is being able to register when something has been acted upon and when something is just an observation. You will need to read about this; I will give you some literature,” she said.
Dr. Naucki gave him some references on the topic (see the recommended reading below if you are also curious to get an introduction to the field). Johan browsed quickly through the literature, but he was a very pragmatic person. He wanted to get hands-on experience with some data, so just a few days later, he came back to Dr. Naucki.
“So, I would like to practice by testing some algorithms on causal discovery. Can I use some test data?” Johan inquired. “Well, certainly not our research data. Aside from data handling protocols, it wouldn’t be of much use to you because, well, you don’t know yet what causal relationships are hidden behind,” replied Dr Naucki.
“So, what can we do?” asked Johan. “You should do tests with known databases. If the causal mechanisms behind the data are known, they are called a ‘ground truth’. Some cause-and-effect relationships can be derived from physical laws. In other cases, you can generate synthetic data by simulation using a ground truth that you impose,” she replied. Johan reformulated to be sure he understood: “Aha, so the game is this: I invent a set of causal relations, in the form of a (directed, acyclic) graph, and then I simulate and record cases of these random variables to generate a database. Then I try to recover the causal graph from the data records alone”.
“Yep, that is one of the typical tasks that mathematicians and statisticians do to invent and benchmark causal discovery tests,” explained Dr. Naucki. “Other times, you test against experimental data with a known ground truth, such as a physical law, like in the example of altitude and temperature.”
“And where can I find such databases to learn and test?” Johan was getting impatient. “Well, there are many repositories with statistical databases, but what you need is not only a database of records, but a database plus a causal graph. This is not so common to find. Fortunately, you can have a look at this Zenodo community from MaRDI, where you can find research data that contains databases together with their ground truth or their causal graph for analysis. You will find both synthetic databases, created from an a priori causal graph, as well as experimental data tagged with known ground truths. These datasets are often linked to research articles that you can find referenced in Zenodo,” replied Dr. Naucki while typing an email with some links from her laptop.
The MaRDI group on Graphical Modelling and Causal Inference (GMCI), part of the Task Area on Statistics and Machine Learning, has started a curated collection of databases and notebook analysis in the Zenodo platform to support researchers and practitioners of this field.
2. Structural-learning algorithms
Sascha is a professional statistician working in causal inference. Her speciality is inventing and implementing algorithms that learn the structure of a model from data. Some of these algorithms are tailored to particular cases. For instance, if the data at hand comes from a Multivariate Gaussian distribution, her algorithm might find that structure fast and with high probability. Structural learning is not easy without prior assumptions, and choosing a model is always an act of balance between simplicity (say, number of free parameters) and detail (or fit). Simply put, a linear regression is much easier for the practitioner to handle than some high-dimensional curve, even if the latter might hit more data points.
Sascha has heard about the MaRDI service and the Zenodo community for GMCI at a conference focusing on graphical models. For her, the key benefit is hosting curated and well-documented datasets: in particular, these datasets make lots of metadata available together with the measured variables, and they supply these, if they exist, with a ground truth. So, for example, if the expert collecting the original data knows that the altitude of a location where her samples are taken influences the temperature measurement she records, she will state that true causal relationship in the dataset's metadata as: altitude → temperature.
Now, for Sascha, this knowledge makes it very easy to validate her algorithms! The truth statement becomes a necessary criterion for fit. That is, if any graphical relationship between measurements that Sascha learns from the data contradicts altitude → temperature or even reverses that relationship, the learned model is undoubtedly not a good fit. The other way around, if Sascha’s algorithms learn reliably that altitude is a predictor for temperature and that any candidate graph representing the model contains altitude → temperature, they can be powerful tools for causal discovery.
3. Joining the community
Peter is a colleague of Sascha; he’s another statistician working on Causality. He has also just discovered the MaRDI project and the GMCI community, so he’s looking at how he can take advantage of these services. Of course, the ability to find curated datasets with labeled ground truths that he can use to benchmark his new algorithms is the first and main advantage. This alone justifies the whole community, but there are other perks that can make his life easier.
Curated and labeled databases are the fundamental ingredient for any statistician, but algorithms and code are also essential to research data. Peter uses a GitHub account to publish his code, but the GMCI Zenodo community also hosts Notebooks. The notebooks are just standard text plus executable script files that can be run on an interpreter (like Jupyter or R). In the GMCI community, for flexibility, the standard file format is .qmd, an extension of the familiar text file format Markdown (.md) that supports executable blocks of code in several languages (and other functionalities). This means Peter can use any of the common programming languages in statistics (R, Python, Julia…) and pack them into a plain text file to share (incidentally, databases are stored in plain CSV files for maximum portability).
The Zenodo community offers a good platform to host and serve databases and notebooks. Still, Peter thinks it would be very nice to have a user-friendly way of looking at the notebooks (including their execution) without the need to download them from the platform and execute them locally. For this, the GMCI community has created the supporting GMCI website, which serves as a portal for the community, and additionally can render featured notebooks as simple non-interactive websites (example) for anyone to read and review the notebook and its execution results quickly.
Peter is quite convinced that this community can help him, making it a centralized and coherent way to share databases, notebooks, and articles. How would he adapt his workflow to enter this community? For someone like Peter, the easiest way to engage with the community is to clone the template repository to have all the scaffolding and then edit it to include his code. Everything Peter needs to do then is to request an upload to the Zenodo repository linked to the GMCI community, and the moderators will review his submission. The process is described in the documentation (here and here), and of course, he can always contact the GMCI curators and other community members for support and exchange.
4. Storing data and DOI, and findability
Alex is an applied mathematician who has recently transitioned from coding to data analysis. Alex is well aware that preparing a dataset for statistical analysis might take far more time than the analysis itself. In one of their recent projects, for example, Alex has looked at some observational soil data colleagues had collected at several sites. Alex has tried to fit a graphical model to understand how different measurement variables may influence the state of a soil sample at a particular location. Being familiar with widely-used tools such as the bnlearn package and its test datasets in R, Alex naively assumed that just a few lines of code might suffice to get a first picture. But then they had trouble understanding what the labels of different columns in the dataset referred to exactly, whether there was any expert knowledge available that might be incorporated into a model, and which measurements were discrete and which were continuous.
This experience is quite common: often, implicit human knowledge or assumptions widely used in a particular scientific field heavily influence an analysis. That information may be passed on from advisor to student and rarely written down. Alex is frustrated by this and firmly believes in the value of FAIR data and metadata. They vow to do better.
So for the next project, this time working on weather prediction, Alex meticulously keeps tabs on data types, the scope of a particular analysis, known temporal structures, ground truth, as well as how they dealt with missing data. When the data has thus been documented and cleaned, Alex feels the bulk of the work is done. Now they can start playing around with different algorithms to find the best-fitting climate model. But wouldn’t it be nice if Alex and colleagues could get to that step directly, drawing from a collection of such well-curated datasets in the future? Yes, but only if the data is findable and supplied with a permissive license!
Knowing that Zenodo provides storage, open licenses, DOIs for findability, and automated metadata handling, Alex believes this is the best location for their data. Then, even better, they find that the Zenodo community for GMCI provides a space for exactly the type of curated datasets Alex has prepared. Checking out instructions for contribution, Alex is impressed that the required metadata fits exactly what they themselves deem essential to document. Great! So Alex contacts the maintainers, gets a quick go-ahead and a final check on their prepared files, and can now be certain that all their good work is out there for others to find and reuse.





Materials from Second Base4NFDI Roadshow Now Available
The recordings, slides, and Q&A from the second Base4NFDI Roadshow in May 2025 have now been published on the BASE4NFDI website. If you missed the event or want to revisit key discussions, all materials are accessible online.
More information:
- in English

Updated Newsblog from NFDI4Biodiversity
Every month, a new short article is published on the NFDI4Biodiversity news page. The blog showcases how NFDI4Biodiversity connects and develops digital tools, data, and collaborations to make knowledge about nature openly accessible for science, conservation, and policy.
More information:
- in German

NFDI Science Slam 2025
Together with Berlin Science Week, NFDI4DS is hosting its annual Science Slam on November 5 at the Weizenbaum Institute in Berlin. Researchers will present their work in a fun and accessible way, inviting the audience to laugh, learn, and connect with NFDI and its consortia. This year’s theme is “Beyond Now”.
More information:
- in English

- “The Book of Why: The New Science of Cause and Effect” by Judea Pearl and Dana Mackenzie (Penguin Books, 2019) is a general introduction to the field of causality, written for the general public.
- Judea Pearl is a pioneer of the field and has also authored the book “Causality“ (Cambridge University Press, 2009), which is a more technical book, with all the foundational ideas of the field.
- For all those who enjoy the pursuit of causal insight, the book "Elements of Causal Inference, Foundations and Learning Algorithms" by Jonas Peters, Dominik Janzing, and Bernhard Schölkopf will be a perfect fit.
- Miguel Hernán, epidemiologist and professor at Harvard, offers the free online course Causal Diagrams, the free book “Causal Inference: What If.”, co-authored with his colleague Jamie Robins, and the software tool CAUSALab, that generates, repurposes and analyzes health data.
- Through chapters by leading researchers from different areas, “The Handbook of Graphical Models” by Marloes Maathuis, Mathias Drton, Steffen Lauritzen, and Martin Wainwrigh (CRC Press, 2018) provides a broad and accessible overview of the state of the art.
- The open research calendar was launchend in 2020, and was created to serve the open research community in collating worldwide open research events into one database. These events are displayed in a Google Calendar.
- In the report on Fraudulent Publishing in the Mathematical Sciences from September 2025, the authors Ilka Agricola, Lynn Heller, Wil Schilders, Moritz Schubotz, Peter Taylor, and Luis Vega analyze the current state of publishing in the mathematical sciences and explain the resulting problems. They offer concrete recommendations, guidelines, and best practices for researchers, policymakers, and evaluators of mathematical research and explain how to detect and counteract attempts to game bibliometric measures, empowering the community to reclaim control over research evaluation and drive necessary change.


"The MaRDI Portal"
{kind=link}

Five short stories on the MaRDI Portal
The MaRDI Portal is a platform that provides the entry point to MaRDI services and the front end of the big MaRDI Knowledge Graph. A mathematics researcher, a PhD student, a computational biologist, a professor, and a math hobbyist embark on their journeys to discover its functionality.
Emma, mathematics researcher
Emma is one of those mathematicians who are good with computations, who enjoy crunching numbers in their head. At family gatherings, she can perform tricks like calculating the weekday of a birth date or squaring a three-digit number on the spot. However, she isn’t a show person and often points out that mathematicians don’t actually spend their time practicing mental calculations; that’s what computers are for. Her work in the Berlin Institute for Advanced Computation focuses on numerical methods. Tweaking an algorithm, using a trick, or finding a novel idea to get more performance out of a machine is deeply satisfying for her.
Her field forms the backbone of countless advances in technology and applied sciences, and Emma enjoys broadening her horizons by browsing scientific fields she is not yet familiar with. Sometimes, her intuition tells her that there may be room for improvement in other experts' computing tools. When that happens, she loves to initiate a collaboration, applying her methods and improving their results.
Emma uses the MaRDI Knowledge Graph – one of the services offered on the MaRDI Portal – to connect with people, check out the research happening locally in her excellence cluster MATH+, and access data related to their research projects. She has often said things like: “Hey, I found out about your research via MaRDI, and I think I can improve the performance of your simulations. Would you like to team up?”, or “I would love to run some tests on your data. Sure, you can send me a link to your server, but what if you stored it in a public dataset repository?” Emma is a strong advocate for FAIR and open data, for collaborations, and for easy reproducibility.
LUCAS, PhD student
Lucas is a PhD student who loves to code. Ever since high school, his passion has been teaching computers to do things. Now, on his way into a career in academia, he has chosen to dive into mathematical modelling and scientific computing. For his thesis, he developed a new algorithm in the field of model order reduction. Before publication, Lucas wants to compare his approach to already published and well-established algorithms that solve the same or similar problems. Ideally, he would like to keep the number of confounders small and compare apples to apples, rather than apples and oranges. So Lucas strives to use the exact same setup, test data, and implementation that his peers used for their results. Only then can he properly benchmark his work and ensure that his ideas are both new and better than what is already out there, helping to advance science.
Finding the best implementation of his peers' algorithms is particularly important to Lucas in order to avoid bias: he spent months tweaking his code and doesn’t feel he has the stamina (or time) to make the effort to reproduce something that's already out there somewhere. To support researchers who may eventually use or even improve his method, Lucas commits to making his own algorithms FAIR and supplementing them with proper documentation, aiming to create impactful, reproducible results. This feels especially useful and important to him, as his first literature and software review leaves him quite frustrated: he struggles to find open-access code and reliable datasets. Lucas wishes for a centralized platform that interlinks source code with datasets in an easily accessible and well-documented way.
Having read the MaRDI Newsletter, Lucas knows that knowledge graphs might solve his problem. Searching for MaRDI online, he finds the portal. Its landing page lists several services based on knowledge graph technology: MathAlgoDB, which he was already familiar with, and, linked to it, the larger MaRDI Knowledge Graph. This is great! Now he can find his peers’ publications and algorithms all in one place, interconnected; making them much easier to discover.
ALEX, computational biologist
Alex is a computational biologist modelling real-world phenomena in their work. They are especially passionate about using science, biology, and mathematics to help humankind better understand the world they live in. For the biological models to be precise, both the input data and the underlying theory need to be sound: high-quality datasets and the best mathematical solving tools are essential. For benchmarking, Alex wants to know who has previously used the same datasets and which model they considered the best fit. Alex's current work focuses on DNA and protein analysis, and they strive to refine and validate models used both within their research team and by the wider community. Alex is convinced that using the latest, most advanced mathematical methods will be the strongest driver of innovation. But even for mathematicians, it is hard to keep up with the rapid evolution of scientific computing; with a background in biology, Alex needs a trustworthy entry point. This is exactly what they find on MathModDB.
To Alex, the MaRDI Portal is a great combination of several useful features: MathModDB provides insight into precisely which mathematical models and variations may solve a particular problem; linked to it, MathAlgoDB offers access to published datasets and implementations; and the larger knowledge graph gathers information about the authors’ publication, all in one place. Happily, Alex discovers that the portal is a community-driven platform: they can contribute themselves! Using the Wikipedia technology stack, Alex can edit their own profile, properly identify it via their ORCID, connect datasets from Zenodo, and code and documentation from their Git instance. This provides all the insight Alex had hoped for, in one place.
SARA, mathematics professor
Sara is a professor of mathematics and is well known for her work in number theory. At recent conferences, her papers and code have easily and successfully passed the newly established technical peer review. She knows that MaRDI has published guidelines for writing and reviewing software in computer algebra. However, she can’t remember where to find the MaRDI contact person to discuss what to include about data handling in her newest funding proposal. Of course, she intends to follow best practices in the community and is aware of the importance of the FAIR principles, but is this all there is to research data management? While searching for MaRDI, she finds their Help Desk and Best Practice services linked on the landing page. This is great.
She contacts MaRDI’s mathematical data consultant, who points her to the MaRDI white paper and the corresponding examples of research data management plans. Sara also learns that MaRDI’s dissemination coordinator is involved in forschungsdaten.info, which collects everything there is to know about mathematical research data management for the wider community, and that the best place to start is on the MaRDI homepage. She checks out this material as well as the best practice report on a mathematical online library called algebraicphylogenetics.org.
Because teaching is also a topic close to Sara’s heart, she decides to order the mobile version of the MaRDI station to be shipped to the next conference she organizes, offering her peers a gamified approach to research data management in mathematics.
Michael, math hobbyist and father
Michael has always loved mathematics, science, and other forms of human knowledge. When he was a child, some fifty years ago, he used to read an illustrated encyclopedia and found every volume interesting. He studied physics at university and considered pursuing a PhD, but ultimately, Michael followed his other great passion: teaching mathematics and physics and unveiling for others the marvels of nature that fascinate him.
Michael loves to follow modern research in maths and physics, updating his course notes every year with new developments. Once hooked on a particular topic, Michael quickly exhausts the few mathematics media aimed at the general public. Not being expert enough to fully understand what he finds when browsing the arXiv, Michael discovered the MaRDI Knowledge Graph, which contains metadata on a vast range of mathematical resources. He is not going to read and check proofs in detail, but he skims abstracts and highlights theorems of articles, and browses the knowledge graph to move from one article to another, to a method, or to a new benchmark result.
Michael has three children. When they were younger, he told them stories about the history of science; now that they are growing up, he shares with them the more advanced topics he is reading about.
Beatrice, the eldest child, enjoys talking about math with her father and will enter university next year to study mechanical engineering. For her, science is like jumping down a rabbit hole: you see an interesting subject, totally abstract and seemingly unconnected with anything you do, and suddenly you find yourself deep inside unexpected terrain. Together, Beatrice and Michael explore the MaRDI Portal, especially the MaRDI Knowledge Graph. Beatrice has always enjoyed imagining spaces deforming, and learning that different branches of geometry exist: topology, differential geometry, algebraic geometry… While browsing, Michael comes across some surveys about how topological spaces and algebraic singularities can be applied to describe the motion and stability of robot arms with different degrees of freedom. That strikes a chord with Beatrice, given her interest in robotics and engineering, and she decides to base her final project in high school on these ideas.
Robert, two years younger than Beatrice, struggles with the pressure of choosing a path in life. Biology and computer science are his favorite subjects, and Michael tries to help him see some connections between these. Robert was fascinated learning in school that biological classifications of species can be done by means other than just visual observation of characteristics. In fact, with DNA and protein sequencing, biologists can model so-called phylogenetic trees to relate different species, even extinct ones, leading to breakthroughs in evolutionary biology. Measuring and classifying these trees is a mathematical problem, while implementing these classifications and data structures is a computer science problem. Exploring the MaRDI Knowledge Graph, Michael found databases and resources for research in phylogenetic trees using algebraic methods, such as algebraicphylogenetics.org, which Robert found extremely interesting. He discovered that “computational biology” is a field, and he got a glimpse into what the people in this field do and what their research is about.
Richard, now in primary school, is still too young to explore the MaRDI resources on his own, but from time to time his father fishes out some “gold nuggets” for him. Richard likes prime numbers and classical Euclidean constructions, such as drawing regular polygons. Michael has used the MaRDI Knowledge Graph to find Richard good math books for children, formulas to calculate pi, and descriptions of mechanical devices for drawing plane curves on paper (his sister Beatrice helped him build some ellipsographs). Of course, Michael does not push the formalities, but Richard proudly tells his schoolmates that sometimes you can add an infinite amount of numbers and still get a finite result. And even when summing seemingly normal fractions, if you add an infinite number of them, you can get surprising results like the number pi!
MaRDI (its services, portal, knowledge graph…) is a project primarily for and from researchers, so a priori, Michael would not be part of its target public. However, MaRDI embraces an open paradigm of science and research, on which FAIR data is not only open to all researchers, but to all citizens with an interest in science and research. Michael never followed the path of a traditional researcher, but his lifelong commitment to teaching has left its mark. He often tells his students that true knowledge isn’t just about solving equations, but about asking the right questions — questions that open doors to entirely new worlds, just like a portal.


Minisymposium about Mathematical Research Data
MaRDI will organize a minisymposium titled "Mathematical Research Data in the Era of AI" at the 2025 ÖMG-DMV conference from September 1-5. The minisymposium will explore the integration of artificial intelligence in mathematical research, focusing on data management, analysis, and the development of AI-driven mathematical tools.
More information:
- in English

Registration now open for CoRDI 2025
The 2nd Conference on Research Data Infrastructure will take place from 26 to 28 August at RWTH Aachen. Highlights include eight thematic tracks, keynotes by Robert Finn (EMBL-EBI) and Cathrin Stöver (GÉANT), poster sessions, and a market of opportunities.
More information:
- in English

National Conference on Data Trustee Models 2025
The DaTNet Competence Network provides information, builds expertise, and fosters exchange on key topics for data trustee initiatives, including legal, technical, organizational, business aspects, and policy frameworks. This year's conference, "Data Sharing for Digital Innovation," will take place in Darmstadt from September 30 to October 1, 2025.
More information:
- in German
- The NFDIxCS team at the University of Potsdam has interviewed thirteen international experts from various disciplines who are implementing best practices in research data and software management. The book “New standards: Conversations on research data and software management” was published in print in March 2025 and can be requested here. A digital publication is planned for the fall/end of the year.
- The NFDITalk "Identity, Trust and Data Access: Identity Attributes in the Context of Research and Regulation" given by Ronny Stritzke (Software Architect, Bundesdruckerei GmbH) on June 16th, 2025, is now available on YouTube.
- The presentation on Persistent Identifier Services 'PID4NFDI' by Sara El-Gebali (Datacite) on May 22, 2025, at the 2nd roadshow of Basic services of the NFDI also uses different fictional characters, similar to the personas in our main article.
- The authors of the paper "Making mathematical online resources FAIR: at the example of small phylogenetic trees" discuss the process of transforming a mathematical library from the early 2000s, the Small Phylogenetic Trees, into a FAIR, modern, and sustainable repository for data from algebraic phylogenetics.
- The report on the third NFDI_BB (Berlin-Brandenburg) network meeting, 'AI as an enabler for science', held at the Weizenbaum-Institute on May 21st, 2025, along with the presentations, is available on Zenodo.
- The MaRDI station is an educational game about research data management. Different versions are available (different storylines, multi- or single-player, exhibition furniture or mobile version, etc.).


Two short stories on the MaRDI Packaging System
1. Reproducing and reviewing results
Dr. Alba Numbs is a researcher in numerics and high-performance computing. She just received a request to peer-review an article submitted for publication in a journal where she collaborates. She received from the editor the manuscript of the authors, a pdf file. The article interests Dr. Numbs since it aligns with her research domain. In the paper, the authors introduce a new algorithm and they describe it broadly, with the key ideas that make the core of their innovation. They also claim to have run several tests comparing their new algorithm with already-known methods, obtaining specific performance advantages for their system. All looks good, but Dr. Numbs would like to test the algorithms to verify the claims of the authors.
More often than she would like to admit, when she refereed articles on new algorithms, she could only do some “static analysis” of the code, essentially meaning that she reviewed the logic of the algorithm as described in the papers, but she could not run the algorithms in practice. In some cases, the authors do not provide any implementation to begin with, code is not part of the submission for publication. The authors certainly have their own implementations, but they don’t make them public, only the overall idea of the algorithm. Dr. Numbs believes this practice should be avoided in academic papers. Fortunately, in this case the authors do have a public repository with the source code.
However, it is often challenging for a third person to install and run all the dependencies and libraries to make a program work that has not been polished enough to be considered production-ready. Research programs are usually just a proof-of-concept demonstration, without much attention to system robustness or stability, and much less user-friendly installations.
In the paper received by Dr. Numbs, the authors included a URL for the GitHub repository, which was indeed online. So, Dr. Numbs browsed the code online a bit, and she cloned the repository on her computer to test. But then, some troubles started. The program contained some scripts in Julia. The authors state they used release version 0.9, but Dr. Numbs has installed version 1.11 on her computer. Dr. Numbs’ version is newer, and she doesn’t want to downgrade her installation for testing, but if an error occurs, she has no way of ruling out that it is related to version incompatibility. The program also has other dependencies: a few command-line programs for utility functions, a bunch of scripts in Python and Go, and C++ compiled source. A build script calls all these dependencies that, Dr. Numbs deduces, must be installed in the author’s computers.
Dr. Numbs was very reluctant to install all these compilers, interpreters, and libraries on her computer just to test someone else’s program. She would not likely use many of these tools again, so that would be polluting her system, not to mention all the time she would need to look for specific versions of the required software and troubleshoot her system for errors. She still remembered last year's “computer apocalypse” after she was asked to review eight software-related articles at the same time for the proceedings of a conference on numerical analysis. She ended up manually installing so many programs and libraries conflicting and overwriting each other that she could not test all the submissions, and she lost several days of work trying to fix everything. Eventually, she had to format the hard drive and install her operating system from scratch to clean up the mess she had on her laptop. This time she was much more cautious, and the more technical issues she found, the more she was tempted to give up and just evaluate the printed paper with a pencil.
Then, she noticed the authors mentioned that they used the new MaPS system from MaRDI, which promises to solve exactly this problem. MaPS allows to create and share runtimes, a kind of container package similar to a Virtual Machine or a Docker container, but tailored specifically for academic researchers.
Dr. Numbs read the documentation and decided to give it a try. She only had to install the MaPS command line program on her Linux computer. Then, she listed all the available runtimes on the MaRDI repositories and, sure, the runtime corresponding to her assigned paper was listed. She then deployed the runtime, which means that MaPS automatically downloaded all the necessary files, and in Dr. Numbs's home folder appeared a directory tree mimicking the filesystem of the operating system that the authors packaged, including all the programs, compilers, and libraries that the authors used in their work.
Dr. Numbs then could run the runtime, meaning that she got a shell on the virtual system* as if she were there (like logging into a system via SSH). Once in that virtual environment, she could list the files to, sure enough, find the same files she could get from the GitHub repository. She could then follow the tests and benchmarks from the paper by trying them out live, almost like following a tutorial. MaPS allows editing any file within the runtime, so Dr. Numbs saved her own notes and results from tests on her system. Programs from within the runtime cannot change anything in the host operating system, making it safe, but the host OS can put and take files in the guest filesystem.
Dr. Numbs was delighted with the system. She could not only reproduce all the results claimed in the paper but also try out her own examples, trying difficult cases, and testing out the limitations of the new algorithm. That gave her incredible capability to evaluate and, even more, to give feedback on the implementation of the algorithm. For instance, she found a bug in the code that appeared in some edge cases. She decided to communicate it back to the authors via editorial correspondence instead of opening a GitHub issue to preserve her anonymity as referee. She thought that the bug was solvable, so she encouraged the authors to make a fix before publication.
After a few days of working on the review and a couple of reports and answers exchanged anonymously with the authors, she was done with this project. She decided to keep the runtime on her computer for archiving purposes since it did not occupy a lot of space, and she had some notes and test data of her own in the runtime. She could, however, delete it completely and download it again from scratch if she needs it in the future. It is indeed a useful system for archiving since it ensures the possibility of execution in the future, even in different host systems. Dr. Numbs was most happy that her work computer was not polluted in any way with any installed program or library. The only exception was the MaPS command line tool which, she suspected, she would use again.
2. Packing your data
Bernard Vir is a PhD student in computational biology, studying protein folding problems. He works with his advisor within a quite prolific research group. He is in his second year, and he has been getting used to the workflow in his laboratory. He receives some experimental data, and he feeds some machine learning models to train a system to predict protein folds and some biological consequences. He needed to get familiar with the software tools his advisor and the group uses. There was a core model, programmed in R, using programs and tools dating back 15 years that a now-retired professor started. Bernard’s advisor uses that too, so they need to keep doing things compatible with that legacy model for practical purposes. Another colleague in his department made a more modern version of the system in R, but it is not fully compatible. Nevertheless, a substantial part of the group researchers use the new version. On top of that, Bernard prefers using TensorFlow and Python for handling most of the machine learning tasks. Then there are graphic interfaces that they access via the web, made in Node and Javascript. There are bindings and interoperability layers that make all work together, but the system is tricky to install and get working.
One of the tasks assigned to Bernard is to organize and clean all the software systems in his lab as part of a broader Research Data Management Plan. He decides to use MaPS. The group publishes about 6-7 papers per year (amongst all the researchers in their group), and the majority of these papers contain some software simulation or computational results. Of course, there is quite a bit of discussion in the department, with some people wanting to keep the legacy toolchain, and some wanting to use the more modern one. Since he wouldn’t force people to change their tools, Bernard decided to create several base runtimes in MaPS for them.
When creating a new runtime from scratch (initializing a runtime), MaPS proposes a quite minimal Linux Debian image by default. You can initialize a runtime and then start it in sandbox mode, meaning that any changes you make are intended to be exported. Bernard created two runtimes, one called Proti1 with the legacy core libraries and another Proti2 with the modern libraries. Each one of these runtimes has its own tools, interpreters, and libraries. Then each researcher that authors a paper inside the group can take any of the two runtimes and expand it with the code developed in their research, using R, Python, or any system of their preference.
Researchers do their daily coding and testing in their own (host) operating systems, but anything that is meant to be associated with a publication must be eventually packed in a MaPS runtime, and tested in the guest OS. Every time a researcher in the group is about to publish a paper, they must freeze a runtime by doing a commit, so its state is saved. This runtime will stay associated with the article. To share runtimes more easily, you can upload the runtime to a remote repository. Bernard contacted the MaRDI team to start their own MaPS repository in their university**, for the runtimes of their research group, since they expect to grow by 6-7 runtimes per year. The permanent link to the repository is included in the published article, so both parts stay connected. An open-access version of the article is included in the runtime for convenience.
This new system allows all the members of Bernard’s research group to easily exchange their code together with a runnable environment, regardless of their preference for the legacy or modern kernel model. Readers of the articles will also benefit from accessing the same runtimes as the authors have. Any runtime they produce must be accompanied by a metadata description of what tools are installed in the runtime, and how it was set up, so the toolchain can be replicated outside that runtime if necessary. Finally, the repository will also serve as an archiving and backup library, which will work in addition to the git repository they already use.
Bernard explains the system to his department, by organizing some training sessions. While this is a new tool to learn, they all agree that they need something better than their current situation. They also have other tech training sessions for newcomers, in which new (or not new) researchers learn how to use Git, LaTeX, data management protocols, and other tools and good practices to handle their research data. Having clear answers and good tools to address these issues makes all the researchers’ lives a bit easier.
You can find all the information about MaPS and try it out on the project's official page. For all your technical questions, you can refer to the main developer of MaPS, Aaruni Kaushik.
* It is possible to run automatically a program or script immediately after launching a runtime, look for the manifest file in the documentation. This can be useful in some contexts when the packaged program is interactive. For non-interactive scripts, the user may find it more useful the shell interface to explore the scripts and run them manually.
** Currently, only one MaPS repository exists, hosted at http://repo.oscar-system.org/. Multiple, decentralized repositories are possible if needed, but the default one does not require extra configuration. Contact the MaPS team to ask more about it.




NFDI network meeting "AI as an enabler for science"
The third edition of the NFDI network meeting, bringing together all consortia active in the Berlin-Brandenburg region, will take place on May 21st at the Weizenbaum Institute in Berlin. The event will feature a combination of invited presentations and demonstrations from consortia and the broader community, providing a platform for discussions and networking.
More information:
- in English

New lecture series on social media data
The working group Social Media Data in Research Practice, an initiative of NFDI4Culture in collaboration with BERD@NFDI, KonsortSWD, and Text+, continues its Show & Tell lecture and discussion series. In 2025, the series will focus on the handling of social media data in research on right-wing extremism and democracy studies. The first Zoom session was on February 28; upcoming dates are April 25 and June 20.
More information:
- in English
Services Roadshow by Base4NFDI
These two-day online sessions focus on the basic services currently being developed within the NFDI community. Day 1 (May 22) is aimed at infrastructure providers, while Day 2 (May 27) is designed for researchers and users. Participants can expect presentations from various NFDI consortia, case demonstrations, and Q&A sessions.
More information:
- in English

Data Week Leipzig 2025
Data Week Leipzig 2025 will take place from 10-13 June 2025 and is set to bring together experts from science, business, and society to explore the diverse perspectives of data and its applications. The event will feature workshops, training sessions, and hackathons. Many sessions will take an interdisciplinary approach, focusing on key topics such as data, digitalization, and artificial intelligence.
More information:

- The article Predefined Software Environment Runtimes as a Measure for Reproducibility by Aaruni Kaushik (see Data Date above) is a good read for anyone considering using MaPS. It is also available as part of the conference proceedings of the International Congress on Mathematical Software 2024 at Springer Nature. The corresponding slides are also available.
- In software, “dependency hell” refers to the problem of managing many pieces of software that must work together but can be incompatible. Humorous depictions from XKCD are here and here. You can also read about it on Wikipedia.
- The Journal of Data- and Knowledge-Integrated Simulation Science (JoDaKISS) is a new open-access journal committed to scientific quality testing of data sets and software for simulations. It opens up new ways for scientists to publish them. The inaugural editorial board involves several MaRDI team members. Read more about this international cooperation for transparent and reproducible simulation science.
- Interested in playful data-driven challenges? Data Hunters is an interactive, team-based card game for 8 to 40 participants that puts you in the middle of real-world dilemmas in research and data management.
- Listen to the German podcast episode "Software Kompetenzen in der Wissenschaft" of the community podcast Code for Thought for research software engineers and researchers who code.


"Browsing the math algorithm database"
{kind=link}

Three short stories on MathAlgoDB
With this newsletter issue, we start a new series of articles, each one focused on one particular MaRDI service. We will name the articles “N short stories on X”, where N ∈ ℕ and X ∈ {MaRDI services}. These will be fictional (or real) stories of people who discover, use, develop, or interact with some of the MaRDI services that we are featuring. We hope that these stories will relate to our readers, directly or indirectly, so they can also discover and use these services as they are intended: to make a mathematical researcher’s life easier, more pleasant, and better integrated within the community.
1. Surveying a subfield of mathematics
Brook is just starting a PhD in scientific computing, specifically in computerized tomography. Their advisor proposes they start getting a good grasp of the field and its classical algorithms. At the same time, the advisor is particularly interested in understanding some new results and comparing them to her own methods. Brook has received a list of references to articles from their advisor. However, following links from the available papers does not lead Brook to code in most cases. A couple of papers linked to personal repositories (which were not peer-reviewed or validated as the papers were), and there was not sufficient documentation to compare or to decide which one works best in each case.
Brook also browses around arXiv but finds it hard to judge whether all relevant material is there and how trustworthy the preprints are. There are no usable AMS or MSC identifiers, either. Which keywords should they use? And how good could the results possibly be?
Brook decides that their best approach is to follow academic social networks and attend conferences in the field. Experts will know which methods work best on what types of problems and can provide some insight into Brook’s advisor’s methods' standing against competitors.
Meeting experts at conferences is very useful, but maybe one of the best pieces of advice they get is to use a curated knowledge graph of numerical algorithms: MathAlgoDB. That would do exactly what Brook wishes to do: understand a field fully by linking papers to code, algorithms, implementations, and benchmarks. This is exactly what they have been looking for!
When Brook first opened the MathAlgoDB site, they had the preconceived idea that such a database should look like a table with columns (fields) like “name of the algorithm”, “inventor”, “book/paper of reference”, “software package that implements it”, etc., and one would have one row on that mental table per each algorithm. Brook also expected to find some search/filter function to prune the table and present the subset of algorithms matching their query.
Instead, Brook finds an interface where you can browse by Problem, Software package, or Algorithm… They start browsing around, and they click on Problems and “Linear Problem (Ax = b)” just to be on the familiar side of maths. They find a page where the subject “ Linear Problem (Ax = b)” is followed by a list of properties: “...specialized by: Symmetric Positive-Definite Linear Problem, Symmetric Linear Problem, etc” then “...is solved by: Biconjugate Gradients, Biconjugate Gradients Stabilized, etc.”
This is not just a database, but a knowledge graph, that is, the “entries” are not uniform registries that you can imagine as a table, but your mental image should be a graph, in which vertices represent different entities: algorithms, publications, software packages, mathematical problems, etc. The edges are named relations between the entities algorithm X solves problem Y, software Z implements algorithm Z, etc.
This knowledge graph model is more versatile than a database (even if, at a low level, the knowledge graph can be implemented on an SQL database). With the knowledge graph paradigm, we can traverse the graph by using meaningful pointers.
Brook now browses MathAlgoDB’s subfield of computerized tomography and finds that algorithms based on completely different ideas are available. Among these are Analytical methods based on filtered back-projection, Brute Force methods based on Algebraic Reconstruction Techniques, and exotic reconstruction methods like Fourier reconstruction or Cormack’s inversion formula. MathAlgoDB directs them to papers and books analyzing and comparing these methods.
For Brook, MathAlgoDB is a great tool for surveying an area of mathematics they are becoming familiar with. Once the knowledge graph becomes increasingly populated, it becomes possible to find all the relevant algorithms, references, and code in a particular field, and you can tailor your own survey study to your specific interests.
2. Let the world know about your algorithm
Christoph has recently started a tenure-track postdoc position. He has worked on his implementations of eigenvalue computation of sparse symmetric matrices for five years, so he has a good knowledge of the underlying theory, and he has developed highly proficient computational skills. Although he has quite a good grasp of his field, he also recognizes limitations when it comes to benchmarking. This is because implementing another researcher’s method in practice is not feasible for him due to time constraints, so it is difficult to precisely assess how his methods compare with those of other researchers. Also, appearances may be deceiving. For instance, implementing code from a verbose description in an article might result in a slower runtime than the author’s implementation, since computational tricks could have been applied by the author, but not mentioned in the paper. Christoph wonders whether it is possible to properly compare methods to find out which implementation of what algorithm is best – and if so, how. He hears whispers over coffee saying that on the upside of missing benchmarks, competitors will not be able to prove Christoph’s methods inferior either.
But Christoph does not consider this a good option. He firmly believes in good scientific practice and in honest comparisons that discern a more performant algorithm from a lesser one. He knows MathAlgoDB is at a valuable development stage, so he checks which algorithms and implementations are already there.
Christoph decides to take two actions. First, he documents his algorithms in MathAlgoDB. He finds that the editor interface of MathAlgoDB makes it easy for him to add to the knowledge graph pointers to his implementation code in GitLab, and to his publications using the DOI that his journal publisher provides. This makes his algorithms publicly available and well-documented. Within a few months of including his algorithms in MathAlgoDB, he starts noticing more inquiries by email from other researchers, and more citations to his work.
The second action requires a bit more time for him to finish. To make an unbiased evaluation of his algorithm, Christoph decides to develop a FAIR benchmark. His benchmark uses Open Data from the application problem that he seeks to solve, so anyone can review how the benchmark is set up, and reproduce the benchmark score independently. He applies the benchmark to his own algorithm, and also to all the competing algorithms that are listed in MathAlgoDB and include an implementation. As he suspected, his algorithm is the best one for the particular case of sparse symmetric matrices, and it is still quite robust in the non-sparse symmetric case. He publishes the results of this comparison, together with a documentation of the benchmark’s workflow in an arXiv article, and stores the program’s code and the open data he used on Zenodo. Finally, Christoph adds the benchmark problem to MathAlgoDB with pointers to the documentation, and connects it to all algorithms and software he compared, making everything findable and accessible.
By leveraging the infrastructure of MathAlgoDB and the FAIR benchmarks, he has obtained a new publication related to his algorithm, he has proven that his algorithm is better than competitors for his specific use case, and he has made it more findable and accessible, getting more citations as a bonus.
3. Get the right tool for your application
Agatha is an engineer with a solid mathematical background. She works in the manufacturing industry. For a particular project, she considers a control system for a mechanical component and wants to simulate it as a passive system.
She knows how to run numerical simulations of PDEs and use Finite Element Methods. Her simulations involve medium-sized input-output parameters, while the computation is done on a very fine discretization grid. With her current methods, and the computer cluster she can access, she can run one simulation every 7 days. Thus, she can only run a few simulations within the time frame of her project, but she would like to run dozens, maybe hundreds of simulations with different parameters. So she is looking for a way to reduce the dimensionality of the entire computation.
She starts researching what mathematical improvements she could apply and finds out about Model Order Reduction. From a quick look at general references, this does exactly what she needs. However, she is not an expert on the topic, and she does not know anyone close enough to ask for collaboration. Certainly, she will not want to implement new numerical methods for this task, so she needs some off-the-shelf solution that is also specifically tailored to her problem.
Then a colleague recommends looking at MathAlgoDB, and she decides to give it a try. Agatha originally thought that MathAlgoDB would be a kind of catalog for numerical algorithms. However, it is more than a curated list of algorithms. MathAlgoDB is a knowledge graph of algorithms, problems, publications, software repositories, and benchmarks.
Agatha starts by trying to find her exact problem of simulating mechanical components. Without surprise, she cannot find that exact problem in the database. She then tries to search for “model order reduction” and finds a list of graph entries classified by type: a few algorithms, lots of publications, and a list of Problems. She decides to browse the algorithms, looking for some keywords she can recognize.
She finds Passive Balanced Truncation, which seems familiar to her. The algorithm has an entry “is surveyed in:” and four publications: the inventing article and three publications that analyze it. The publications lead to a DOI identifier that sends you externally to the article or book in question. One of these looks like an interesting reading list, and Agatha spends a few minutes looking at that article.
That was useful, she thinks. She found that publication by searching semantically for a mathematical problem, and not by using a search engine and trying to match keywords in the article text, as she was used to.
Then she notices that the algorithm also had an “implemented by” entry, pointing to a software package. Agatha navigates there and then exits the knowledge graph again, this time to a GitHub repository with the code implementing the algorithm. It's still not what she is looking for, but again, the code documentation reveals some insights into the problem.
That is also neat, Agatha thinks. She is browsing references like a bibliography, but the references are not only “papers” but also code repositories, databases, etc. Also, these repositories are curated to follow FAIR principles, so they won’t likely disappear tomorrow. On top of that, most of this scientific research software is open source.
After a few hours of browsing MathAlgoDB, Agatha has found publication references, some repositories with code, and indirectly she has collected a list of names of experts in the field. She has enough material to read, program, and potential people to discuss for weeks of research.
One afternoon after work she goes for a drink with some colleagues. She tells them about her experience, still amazed that only some weeks before she was still relying on the popular web search engine to find repositories, names of experts, and everything that is not a publication. Indeed, she was also using it to find most of the publications she read. She was happy that someone put that infrastructure in place.
Her colleagues ask: “Well, did you find a solution within that knowledge graph of yours? Isn’t it better to just use a comprehensive, commercial software suit that implements most of the known and tested algorithms”. She replies, “Sometimes you buy a fancy expensive tool that does everything, you get used to it, and you use it for everything. Sometimes, you prefer to buy a very specialized tool that does one specific job, but much better than anything else. This knowledge graph is like asking a very knowledgeable shop assistant that knows all the tools in the market, and can recommend to you what you really need in your case. And in this case, tools and advice are for free!”.




From Proof to Library Shelf
This catch-up workshop on Research Data Management for Mathematics will take place at MPI MiS in Leipzig from March 17-19, 2025. It will offer feature talks, hands-on sessions, and a Barcamp to discuss mathematical research data, present ideas and services, and network.
More information:
in German

Large Language Models and the future of scientific publishing
Various NFDI consortia are organizing the workshop "Large Language Models and the Future of Scientific Publishing". It will take place at DIPF Frankfurt on February 11, 2025. The workshop will bring together researchers and publishers to identify and address the upcoming challenges for journals and the increased demands on reviewers and the wider research community.
More information
- in English

FAIR Data Fellowships
Applications for this fellowship are open until January 10, 2025. These one-month fellowships, endowed with 1,500 Euros, offer researchers the opportunity to prepare their historical research data for publication with expert guidance on FAIR principles, structuring, and repositories from the five implementing institutions.
More information
The Research Data Management course Schlüsselqualifikation Forschungsdatenmanagement. Ein Kurs in 8 Teilen: Überblick was developed by Björn Schembera and held at the University of Stuttgart. The interdisciplinary course is aimed at students but can also be used and adapted for doctoral students, researchers, or other target groups and is openly licensed.
The article A group theory of group theory: Collaborative mathematics and the ‘uninvention’ of a 1000-page proof by Alma Steingart describes how finite group theorists resolved to produce a ‘second-generation proof’ to streamline and centralize the classification of mathematical objects known as finite simple groups.
In the podcast series Modellansatz (English: The modeling approach) by the research group of Scientific Computing at Karlsruhe Institute of Technology (KIT), you will experience firsthand what the researchers, graduates, and academic teachers at KIT puzzle about.


by Ariel Kahtan, licensed under CC BY-SA 4.0.




NFDI4Objects Berlin-Brandenburg
The first NFDI4Objects meets Friends network meeting will take place on November 7, 2024, in Berlin. This event offers ideas and networking on research data management (RDM) focused on archaeological and object-based data. It will showcase projects, discuss helpdesks, quality assurance, and RDM training.
More information:
- in German

NFDI Science Slam 2024 in Berlin
In cooperation with Berlin Science Week, NFDI4DS will host its annual Science Slam this October at the Weizenbaum Institute in Berlin. Researchers present their work in a simple, humorous way, inviting the audience to laugh, cry, and engage with NFDI and its consortia. This year’s motto is “Crossing Boundaries.”
More information:
- in English

GHGA Symposium 2024 in Heidelberg
The GHGA (German Human Genome-Phenome Archive) will hold a public symposium on 15 October 2024 in Heidelberg, focusing on topics related to enabling data sharing for health research in Germany and Europe. The event will feature presentations from GHGA members as well as renowned experts from various European biomedical data initiatives and projects, including the European Genomic Data Infrastructure (GDI), the German National Cohort (NAKO), NFDI4Health and the genome sequencing model project in Germany.
More information:
- in English
Robin Wilson's book Four Colors Suffice: How the Map Problem Was Solved offers an authoritative historical account of the four-color theorem history and the main mathematical ideas involved. The book is suitable for undergraduates. The 2014 edition includes colored images (the previous one only offered black and white images).
A more casual (and much shorter) read by the same author is his article Wolfgang Haken and the Four-Color Problem, published in 2016.
Quanta Magazine published the public outreach article The Colorful Problem That Has Long Frustrated Mathematicians by David S. Richeson in 2023. Quanta also produced a short video on the topic featuring the author.
The Numberphile YouTube channel published the video The Four Color Map Theorem, featuring James Grime, explaining the topic in layman's terms.
Chris McMullen's book "The Four-Color Theorem and Basic Graph Theory", published in 2020 by Zishka Publishing (ISBN 1941691099, 9781941691090), offers high-school-level puzzles and exercises related to the four-color theorem. It also includes an elementary proof of the theorem (which is not actually a proof, but it gives insights).
Mathigon (an online platform that combines an interactive textbook and a virtual personal tutor) offers an interactive course on graphs and networks, which includes a chapter on Map Coloring.

“I’m a mathematician and I use no data. Change my mind.”
At the MaRDI team, we continuously communicate the project's goals and mission to a general audience of mathematicians. We describe the importance of data in modern mathematics and the FAIR principles and show examples of the services that MaRDI will provide to some key communities represented in MaRDI’s Task Areas: computational algebra, numerical analysis, statistics, and interdisciplinary mathematics.
However, our audience often consists of mathematicians working in other areas of mathematics, maybe topology, number theory, harmonic analysis, or logic… who consider themselves not very heavy data users. In fact, the sentence “I have no data” is a statement that many mathematicians would subscribe to.
In this article, we transcribe fictional (but realistic) questions and answers between a “no-data” mathematician and a “research data apostle”.
I do mathematics in the “traditional” way. I read articles and books, discuss with collaborators, think about a problem, and eventually, write and publish papers. I use no data!
Maybe we need clarification on the terms. We call “Research Data” to any information collected, observed, generated, or created to validate original research findings.
If you think of a large database of experimental records collected for statistical analysis, or if you think of the source code of a program, yes, these can be examples of research data. However, there are many other types of research data.
You probably use LaTeX to write your articles and BibTeX to manage your lists of bibliography references. You probably use zbMATH or MathSciNet to find a bibliography and arXiv to discover new papers or to publish your preprints. Your LaTeX source files and your bibliography lists are examples of research data. Without a data management mindset, you wouldn’t have services like zbMATH or arXiv.
But there is more data than electronic manuscripts in your research. If you find a classification of some mathematical objects, that list is research data. If you make a visualization of such objects, that is research data. Every theorem you state and prove can be considered an independent piece of abstract research data. If you have your own workflow to collect, process, analyze, and report some scientific data, that workflow is in itself a valid piece of research data.
Many mathematical objects (functions, polytopes, groups) have properties that you can address in your theorems. For instance “since the integral of this function can be bounded by a constant C<1…”. Such properties are collected in data repositories (DLMF, etc.) that provide consistent and unified references to gather these data.
You should think of research data as any piece of information that can be tagged, processed, and built upon to create knowledge in a research field. This perspective is useful for building and using new technologies and infrastructure that every mathematician can benefit from.
I think you say “everything is data” to give the impression that MaRDI and other Research Data projects are very important… but how does your “data definition” affect me?
It is not a mere definition for the sake of discussion. We believe there is a new research data culture in which mathematicians from all fields should participate. A research data culture is a way to think about how we organize and structure all the human knowledge about mathematics, how we store and retrieve that knowledge, the technical infrastructure we need for that, and ultimately, how we make research easier and more efficient.
Imagine you are looking for some information that you need in your research. When you look for a result, the “unit of data” would be a theorem (probably together with its proof, a bibliographic reference, an authorship…), but not an article or a book on themselves. So, it is more useful to consider that your data is made up of theorems instead of articles.
Then, your theorems will fit into a greater theory in your field. Sure, you can explain this in your article and link to references in your bibliography, but you will probably not link to specific theorems, likely sometimes you will miss some relevant references, and certainly you can’t link to future works retroactively. By thinking about your results as data and allowing knowledge infrastructures to index and process them, your results will be put in a better context for others to find, access, and reuse them. Your results will reference others, and others will reference yours. Furthermore, they will withstand better the evolution and advances in the field.
I thought MaRDI was about building infrastructure to manage big databases and code projects. Since I don’t use databases or program, why should I be interested in MaRDI?
MaRDI is much more than that. It is true that mathematicians working with these types of data (large databases, large source code projects, etc. …) need a reliable infrastructure to host and share data, standards to make data interoperable, and a way to work collaboratively in large projects. MaRDI addresses these needs by setting task groups that develop the necessary infrastructure in each domain (for instance, in computer algebra or statistics).
But as we mentioned above, there are many other types of data: classifications of mathematical objects, literature (books and articles), visualizations, documentation of workflows, etc. MaRDI takes an integral approach to research data and addresses the needs of the mathematical community as a whole.
For instance, MaRDI bases its philosophical grounds on the FAIR principles. The acronym FAIR means that research data should be Findable, Accessible, Interoperable, and Reusable (read our articles on each of these principles applied to mathematical research). These principles are now widely accepted as the gold standard for research data across all scientific disciplines, and they are the grounds for all other NFDI consortia in Germany and other international research data programs.
Following FAIR principles is relevant for all researchers. Your results (your data) should be findable for other researchers, which implies caring about digital identifiers and indexing services. Delegating and thrusting third-party search engines is not a wise strategy. Your research should be accessible, meaning you should be concerned about publication models, the completeness of your data, or your meta-data structure. Your data should be interoperable, meaning you should follow common practices in your community to exchange data. At the very least, this could mean following common notation and conventions for your results so they can be translated across the literature with minimal context adaptations. Finally, you should always keep in mind that the most important FAIR principle is reusability. Reusability is the base of verifiability. Document your thought processes. Sharing insights is as important as sharing facts. Research that is not reused is barren.
MaRDI aims to spread this research data culture by raising awareness of these principles and encouraging discussions to devise best practices or address challenges in concrete, practical cases. Since these discussions affect all mathematicians, it is a good reason to be interested in MaRDI.
Furthermore, MaRDI strives to develop services that best help mathematicians. Aside from the specific services developed for the aforementioned task areas, MaRDI addresses all mathematicians with its main and central MaRDI Portal, a knowledge base to better manage all mathematical knowledge from a research data perspective. MaRDI also lays bridges to communities that can impact mathematics and the research data paradigm, like the formalized mathematics community, which is taking an increasing role in mathematical fields other than logic or theoretical computer science.
Why do you talk about political / philosophical / ethical questions? Shouldn’t MaRDI be just a technical project?
To build an infrastructure for the future of mathematical research data, planning must be accompanied by a serious reflection on the guiding principles. The FAIR principles we mentioned before are not a technical specification of concrete implementations but a set of philosophical rules that researchers should apply to their research data. The implementation and the guiding principles cannot be independent.
MaRDI encourages a debate and calls researchers to decide on challenging situations concerning research data. For instance, which are the best publication practices? Should researchers publish in traditional journals? In Open Access journals? Should they also publish a version (identical or preliminary to the final one) on preprint services such as arXiv? Should the pay-per-publish practice be accepted? How can we ensure the publication quality in that case? These questions are one particular topic related to handling research data; thus, they fall into the area of interest of MaRDI.
MaRDI will not dictate absolute answers to these questions, but it will try to stimulate and facilitate discussion about these delicate topics in the community. It will promote principles and common grounds that the entire community of mathematicians can agree on. Then, MaRDI will help build the necessary infrastructure to put these principles into practice.
MaRDI is neither a regulating agency nor a company offering products and solutions. MaRDI is a community of mathematicians. To be more precise, MaRDI is a set of different communities (computer algebra, numerical analysis, statistics and machine learning, interdisciplinary mathematics) of mathematicians that collaborate to create a common infrastructure and to promote culture for mathematical research data. MaRDI is scoped in Germany but it has a clear universal vocation, other communities of mathematicians from anywhere may complement MaRDI in the future. Thus, MaRDI is a technical project when its members, researchers who face a specific challenge, define technical specifications for the infrastructure to build. But MaRDI is at all times a social and philosophical project since its members endeavor to build the tools for mathematical research in the future.
So, should I rewrite my papers thinking on “Data”?
Research articles and books are and will probably always be the primary means of communicating results between researchers. You should write your papers thinking of your peer mathematicians who will read them. Your research paper is the first place where some theorem is proved. It gives you authorship credit, and as such, it establishes a new frontier of mathematical knowledge. But at the same time, your papers can contain several types of data that can be extracted, processed automatically, and potentially included in other knowledge bases.
Imagine your paper proves a classification result about all manifolds of dimension 6 that satisfy your favorite set of properties. What about other dimensions? What about slightly different properties? Your result fits in a broader picture to which many mathematicians contribute. At some point, it will make sense to collect all these results somewhere to have a more complete presentation. This can be a survey article/book, but sometimes it is better to have it in the form of a catalog. In this case, it would be a list of all manifolds classified by their invariants or by some characteristics. This catalog would serve as a general index, the place to look up what is known about your favorite manifolds, and from this catalog, you can get the references to the original articles.
We can go further and ask whether a catalog is the best information structure we can aim for. At MaRDI, we support knowledge graphs as a way to represent all mathematical knowledge. In a knowledge graph, every node is a piece of information (a manifold, a list of manifolds, an author, an article, an algorithm, a database, a theorem…), and every edge is a knowledge relationship (this list contains this manifold, this manifold is studied in this article, this article is written by this author…)
You can help build this knowledge graph of all mathematics by thinking about and preparing your research data for inclusion in it.
I tried the MaRDI Portal to search for one of my research topics. It returned several article references that look very much like zbMATH Open. Why do we need another search engine?
First, keep in mind that the Portal is still under development. Second, it’s not a surprise that you obtained article references looking like zbMATH Open. It is exactly where they come from. MaRDI does not intend to substitute zbMATH or any other catalog or database, instead, it aims to integrate them in a single place, with a richer structure.
zbMATH is a catalog, the MaRDI portal is a knowledge graph. The MaRDI knowledge graph includes already (partially) the zbMATH catalog, the swMATH software catalog, the Digital Library of Mathematical Functions (DLMF), the Comprehensive R Archive Network (CRAN), and the polyDB database for discrete geometric objects. Eventually, it will also include other sources like arXiv and more. The MaRDI knowledge graph imports the entries of these sources and gives them a structure in the knowledge graph. Some links on the graph are already provided by the sources, like one article reference points to other articles cited in the bibliography. A challenge for the MaRDI KG is to populate many more links between different parts of the graph, like “This R library uses an algorithm described in this article”.
Imagine this future: You learn about a new topic by reading a survey, attending a conference, or following a reference; and you think it could be useful for your research. With a few queries, you find everything published in that research direction. You can also find which researchers and universities or research institutes have people working in that field, in case you want to get in contact. You have easy and instant access to all these publications. You query for some general information that is scattered across many publications (e.g., what is known about my favorite manifolds in any dimension). You get answers that span all the relevant literature. Refining your query, you get more accurate results pointing to specific theorems which are relevant to you. Results found by automatic computation (theorems but also examples, lists, visualizations…) come with the code you can run and verify easily in a computer virtual machine. Mathematical algorithms that can be used as a pure tool to solve a concrete problem can be found and are plug-and-play into any software project. Databases and lists of mathematical objects are linked to publications, and all results are verifiable (maybe even with a formalized mathematics appendix). The knowledge graph gives you an accurate snapshot of the current landscape of mathematical knowledge, and rich connections arise from different fields. You can rely on the knowledge graph not only as a support tool to fetch references but also as your main tool to learn and contribute to mathematical research. This future is not yet here, but it is a driving force for those who build MaRDI.



Workshop on Scientific Computing
The MaRDI "Scientific Computing" task area focuses on implementing the FAIR principles for research data and software in scientific computing. The second edition of their workshop (Oct 16 – 18, 2024, in Magdeburg) aims to unite researchers to discuss the FAIRness of their data, featuring presentations, keynote talks, and discussions on topics like knowledge graphs, research software, benchmarks, workflow descriptions, numerical experiment reproduction, and research data management.
More information:
- in English
EOSC Symposium 2024
The symposium will take place from 21 to 23 October 2024 in Berlin. It is a key networking and idea exchange event for policymakers, funders, and representatives of the EOSC ecosystem. The symposium will feature a comprehensive program, including sessions on the EOSC Tripartite Partnership, collaborations with the German National Data Infrastructure (NFDI), and a co-located invitation-only NFDI event.
More information:
- in English
From proof to library shelf
This workshop on Research Data Management for Mathematics will take place at MPI MiS in Leipzig from November 6-8, 2024. It will offer feature talks, hands-on sessions, and a Barcamp to discuss mathematical research data, present ideas and services, and network.
More information:
- in German
The review Making Mathematical Research Data FAIR: A Technology Overview by Tim Conrad, Eloi Ferrer, Daniel Mietchen, Larissa Pusch, Johannes Stegmuller, and Moritz Schubotz provides a technology review of existing data repositories/portals focusing on mathematical research data.
In the paper A FAIR File Format for Mathematical Software, Antony Della Vecchia, Michael Joswig, and Benjamin Lorenz introduce a JSON-based file format tailored for computer algebra computations, initially integrated into the OSCAR system. They explore broader applications beyond algebraic contexts, highlighting the format's adaptability across diverse computational domains.
The video FAIR data principles in NFDI by NFDI4Cat provides an in-depth exploration of research data management tools and FAIR data principles. The video also examines how these tools are applied in experimental setups. Whether you're a researcher, data enthusiast, or simply curious about the future of data management, this video will provide valuable insights and actionable takeaways.
The position paper A Vision for Data Management Plans in the NFDI by Katja Diederichs, Celia Krause, Marina Lemaire, Marco Reidelbach, and Jürgen Windeck envisions an expanded role for Data management plans within Germany's National Research Data Infrastructure (NFDI), proposing their integration into a service architecture to enhance research data management practices.



A Modern Toolbox for Mathematics Researchers
What mathematicians need
It is often said that mathematicians only need pen and paper to do their job. Some elaborate on it as a joke by saying that a trash bin is also necessary, unlike the case of philosophers. Other quotes involve the need for coffee as fuel to feed the theorem-producing devices that are mathematicians. Jokes aside, it is true that mathematics research requires, in general, a relatively small infrastructure and instruments compared to other, more experimental research fields. However, two conditions are universally needed for research. Firstly, researchers need access to prior knowledge. This is addressed by creating publications and specialized literature and collecting resources in libraries and repositories to offer access to that knowledge. Secondly, researchers need to interact with other researchers. This is why researchers gather in university departments and meet at conferences. Many mathematicians love chalk and blackboard. While this is another method of writing, it serves an exchange purpose, it allows two or more people, or a small audience, to think simultaneously on the same topic.
These needs (literature and exchange spaces) are universal, have been unchanged for centuries, and will remain the same for the future. The basic toolset (pen and paper, books and articles, university departments, conferences, chalk and blackboard…) will likely stay for a long time. However, the work and practice of science researchers in general, and mathematics researchers in particular, evolves with the times of society and technology. Today’s researchers require some other specialized tools to address specific needs in contemporary research. They use digital means to have practical access to the literature, and to communicate quickly and efficiently with colleagues; they use the computing power of machines to explore new fields of math; they use managing tools to handle big amounts of data, and to coordinate distributed teams to work together. In this article, we will walk through some of the practical tools that changed the practice of mathematics research at some point in history. Some of these tools are technological changes that impacted all of society, such as the arrival of the web and the information era. Some are a consequence of changes in the way the mathematics field evolves, such as the increasingly data-driven research in mathematics that MaRDI aims to help support. We will also review some initiatives that try to change some current common practices (the CRediT system for attributing authorship), and finally, we will speculate with some tools that may one day become a daily resource for mathematicians (the impact of formalized mathematics in the mathematical practice)
From the big savants to an army of experts
We could start revisiting history with the Academy of Athens or the Library of Alexandria as “tools and infrastructure” for mathematicians in ancient times. Instead, we will directly jump to the 17th and 18th centuries, with some giant figures of mathematics history like Descartes, Newton, Leibniz, or Gauß. They were multidisciplinary scientists making breakthroughs in mathematics, physics, applied sciences, engineering, and even beyond, like philosophy. Mathematics at the time was a cross-pollinating endeavor, in which physics or engineering problems motivated mathematics to advance, and math moved the understanding of applied fields forward. The community of these big savants of the time was relatively small, and they mostly knew about each other. They mainly used Latin as a professional communication language, since it was the cultivated language learned in every country. They maintained correspondence by letter between them and published their works generally as carefully curated volumes since publication and distribution was a costly process. Interestingly, it was also in the 17th century when the first scientific journals appeared, the Philosophical Transactions of the Royal Society and the Journal des Sçavans of the French Academy of Sciences (both started around 1665). These were naturally not devoted only to mathematics or to a specific science, but more to a very inclusive notion of science and culture. Still, the article format quickly became the primary tool for scientific communication.
Fast-forward a century, and in the 19 hundreds the practice of scientists changed significantly. Mathematics consolidated as a separate branch, where most mathematicians only researched mathematics. Applications still inspired mathematics, and mathematics still helped solving application problems, but by this century most scientists focused in contributing to one aspect or another. This was a process of specialization, in which the “savants” capable of contributing to many fields were substituted by experts with more profound knowledge in a concrete, narrower field. In this century we start finding exclusively mathematical journals, like the Journal für die reine und angewandte Mathematik (Crelle’s Journal, 1826). By the end of the century (and beginning of the 20th century) this specialization process that branched science into mathematics, physics, chemistry, engineering, etc. also reached each science in particular, branching mathematics into different fields such as geometry, analysis, algebra, applied math, etc. Figures like Poincaré and Hilbert are classically credited as some of the last polymathematicians, capable of contributing significantly to many, almost all the fields of mathematics.
During the 20th century, the multiplication of universities and researchers due to broader and universal access to higher education brought much more specialized research communities. The number of scientific journals proliferated accordingly, and the publication rate and the creation of articles outpaced the classical book format. With so many articles, came the need for new bibliographic tools like catalogs (Zentralblatt MATH and Mathematical Reviews date back to 1931 and 1940, respectively) and other bibliometric tools (impact factors started to be calculated in 1975). These reviewing catalogs have been, for decades, for many mathematicians, a primary means of disseminating and discovering what was new in the research community. Their (now coordinated) Mathematical Subject Classification also brought a much-needed taxonomy to the growing family tree of mathematics branches. The conference format, in some cases with many international participants, also consolidated as a scientific format, a way to disseminate results, and a measure of the prestige of institutions.
The computing revolution
The next period we will consider starts with the irruption of computers, later accelerated with the addition of the Internet and the web. Computers have impacted the practice of mathematics at two levels. On the one hand, computers seen purely as computing machines have opened a new research field in itself, computer science. Many mathematicians, physicists, engineers… turned their attention to computer science in their early days. In particular, mathematicians started exploring algorithms, and branches of mathematics not reachable before computing power was available. For instance, numerical algorithms, chaos and dynamical systems, computer algebra, statistical analysis, etc. These new fields of mathematics have developed specific computer tools in the form of programming languages (Julia, R, …), libraries, computer algebra systems (OSCAR, Sage, Singular, Maple, Mathematica…), and many other frameworks that are now established as essential tools for the daily practice of these mathematicians.
On the other hand, computers have impacted mathematics as they have impacted every other information-handling job: as office automation. Computers help us to manage documents, create and edit texts, share documents, etc. One of the earliest computer tools that most profoundly impacted mathematicians' lives has been the TeX typesetting system. Famously, TeX was created by computer scientist Donald Knuth in more than a decade (1978 - 1989) to typeset his Art of computer programming. However, many use the more popular version LaTeX (or “TeX with macros, ready to use”) released by Leslie Lamport in 1984. Before TeX/LaTeX, including formulas in a text was done either by treating them as images (that someone had to draw manually into the final document, or engrave them into printing plates), or by semi-manual processes of composing formulas by templates on the physical font types. This was a tedious process that was only carried out for printing finished documents, not for drafts or early versions to share with colleagues. With TeX, mathematicians (and physicists, engineers…) could finally describe formulas as they intended to be displayed, and be processed seamlessly with the rest of the text. This had an impact on the speed and accuracy of the publication (printing) process, but also on a new front that just arrived in time: online sharing.
The early history of internet includes first protocols for communicating computers and first military networks of computers (Arpanet), but the real booster for civil research and for society in general was the invention of the World Wide Web by Tim Berners Lee in 1989 at the CERN. It was created as a pure researchers’ tool for exchanging scientific information, and with the goal of becoming a “universal linked information system”. Almost simultaneous to the creation of the WWW was the emergence of another critical tool for today’s mathematicians: the arXiv repository of papers and preprints. Originally available as FTP service (1991) and soon after on the WWW (1993), this repository managed by Cornell University has become a reference and a primary source for posting new works in mathematics and many other research fields. Many researchers offer their preliminary articles there as soon as they are ready to be shared, before sending them to traditional journals for peer-review and publication. ArXiv thus serves a double purpose: it is a repository to host and share results (and prove precedence if necessary), and it is also a discovery tool for many researchers. ArXiv has a mailing list / RSS feed on which you can get daily news about what has been published (or is going to be published) in the specific field of your interest. ArXiv has largely replaced this discovery function previously offered by reviewing services (zbMATH, MR). These catalogs do not host the works; instead, they index and review peer-reviewed articles (zbMATH Open also indexes some categories of arXiv). As indexing tools, these services remain authoritative (complete, with curated reviews, and well maintained), and offer valuable bibliographical data and linked information, but their role as a discovery tool is no longer an undisputed feature.
The data revolution
At this point, we have probably covered the main tools of mathematicians up to the end of the 20th century, and we enter contemporary times. One of the challenges that 21st-century research is facing is data management. Most sciences have always been based on experimentation and data collection, but the scale of data collection has grown to unprecedented levels, often called “big data”. With this term, here we refer both to particular massive datasets bound to a specific project and also to the amount of projects and data (big and small) that flood the landscape of science.
Many data repositories have become essential tools for handling data types other than research papers. In the case of software, Git (2005) and Git repositories (GitHub, 2008) have emerged as the most popular source code management tools, and have mitigated or solved many problems with managing source code versions and the collaborative creation of software.
Digital Object Identifiers (DOIs, 2000) have become a standard for creating reliable, unique, persistent identifiers for files and digital objects on the ever-changing internet. Publishers assign these DOIs to the digital versions of publications, but actually, DOIs are essentially universal labels for any digital asset. Repositories such as Zenodo (2013) offer DOIs and hosting for general-purpose data and digital objects.
In the case of mathematics, as has happened with other sciences, it has dramatically increased its reliance on data, be it experimental (statistics, machine learning…), extensive collections and classifications (groups, varieties, combinatorial…), source code for scientific computing, workflow documentation on interdisciplinary fields, etc. The scientific community, and the mathematics community in particular, has grown bigger than ever, and it is challenging not only to keep track of all the advances, but to keep track of all the methods and replicate all the results by yourself. In response to that, sciences are in the process of building research data infrastructures that help researchers in their daily lives. Here is where MaRDI (and the NFDI for other branches of science) enters as a project to help on that front.
Structuring research data implies, on one hand, creating the necessary infrastructure (databases, search engines, repositories) and guiding principles that govern ethically and philosophically the advancement of science. The FAIR principles (research data should be Findable, Accessible, Interoperable, and Reusable) that we have discussed extensively in previous articles provide a practical implementation of such principles, together with common grounds such as verifiability of results, neutrality of the researcher, or the process of the scientific method. On the other hand, the structuring of research data won’t be successful unless the researchers embrace new practices that are not perceived as imposed duties but are reliable, streamlined tools that make their results better and their work easier.
MaRDI aims to become a daily tool to help mathematicians and other researchers in their jobs. Some of the services that MaRDI will provide include accessing numerical algorithms, richly described, benchmarked, and curated for interoperability; browsing object collections and providing standardized work environments for algebraic computations (software stacks for reproducibility); curating and annotating tools and databases for Machine Learning and Statistical analysis; describing formal workflows in multi-disciplinary research team; and more. All MaRDI services will be integrated into a MaRDI portal that will serve as a search engine (for literature, algorithms, people, formulas, databases, services, et cetera). We covered some of MaRDI services in previous articles and will cover more in the future.
The cooperation challenge
Another challenge many sciences face, and increasingly in mathematics, is the growth of research teams for a concrete research project. In many experimental or modeling fields it is not uncommon to find long lists of 8, 10, or more authors signing an article, since it is the visible output of a research project involving that many people. Different people take different roles: from the person who devised the project, the one who carried out experiments in the lab, the one who analyzed the data, the one who wrote some code or ran some simulations, the one who wrote the text of the paper, etc. Listing all of them as “authors” does not give hints about their roles, and ordering the names by relative importance is a very loose method that does not improve the situation much. This challenge requires a new consensus of good scientific practice that the community accepts and adopts. The most developed proposed solution is the CRediT system (Contributor Roles Taxonomy), a standard classification of 14 roles that intends to cover all possible ways that a researcher can contribute to a research project. The system is proposed by the National Information Standards Organization (NISO), a United States non-profit standards organization for publishing, bibliographic, and library applications.
For reference, we list here the 14 roles and their descriptions:
- Conceptualization: Ideas; formulation or evolution of overarching research goals and aims.
- Data curation: Management activities to annotate (produce metadata), scrub data and maintain research data (including software code, where it is necessary for interpreting the data itself) for initial use and later re-use.
- Formal Analysis: Application of statistical, mathematical, computational, or other formal techniques to analyze or synthesize study data.
- Funding acquisition: Acquisition of the financial support for the project leading to this publication.
- Investigation: Conducting a research and investigation process, specifically performing the experiments, or data/evidence collection.
- Methodology: Development or design of methodology; creation of models.
- Project administration: Management and coordination responsibility for the research activity planning and execution.
- Resources: Provision of study materials, reagents, materials, patients, laboratory samples, animals, instrumentation, computing resources, or other analysis tools.
- Software: Programming, software development; designing computer programs; implementation of the computer code and supporting algorithms; testing of existing code components.
- Supervision: Oversight and leadership responsibility for the research activity planning and execution, including mentorship external to the core team.
- Validation: Verification, whether as a part of the activity or separate, of the overall replication/reproducibility of results/experiments and other research outputs.
- Visualization: Preparation, creation and/or presentation of the published work, specifically visualization/data presentation.
- Writing – original draft: original draft – Preparation, creation and/or presentation of the published work, specifically writing the initial draft (including substantive translation).
- Writing – review & editing: Preparation, creation and/or presentation of the published work by those from the original research group, specifically critical review, commentary or revision – including pre- or post-publication stages.
The recommendation for academics is to start applying these roles to each team member in the research projects, keeping in mind that one or more people can fulfill one or more than one role, and only applicable roles should be used. A degree of contribution is optional (e. g. ‘lead’, ‘equal’, or ‘supporting’).
Using author contributions can be pretty straightforward. For example, imagine a team of four people working on a computer algebra project. Alice Arugula is a professor who had the idea for the project, discussed it with Bob Bean, a postdoc, and both developed the main ideas. Then Bob involved Charlie Cheeseman and Diana Dough, two PhD students who programmed the code, and all three investigated the problem and filled in the results. Bob and Diana wrote the paper, Charlie packed the code into a library and published it in a popular repository, and Alice reviewed everything. They published the paper, and all of them appeared as authors. Following CRediT and publisher guidelines, they included a paragraph at the end of the introduction that reads:
Author contributions
Conceptualization: Alice Arugula, Bob Bean; Formal analysis and investigation: Bob Bean (lead), Charlie Cheeseman, Diana Dough; Software: Charlie Cheeseman, Diana Dough; Data curation: Charlie Cheeseman; Writing - original draft: Bob Bean, Diana Dough; Supervision: Alice Arugula.
For publishers, the CRediT recommendation is to ask the authors to detail their contribution, list all the authors with their roles”, and ensure that all the contributing team assume their share of the responsibility assigned by their role. Technically, publishers are also asked to make the role description machine-readable using the existing XML tag descriptors.
Formalized mathematics
We’ll finish with a more speculative tool that mathematicians may use in their mid-term future. A branch of meta-mathematics that is already mature enough to spread across all other mathematics areas is formalized mathematics. Once just studied theoretically as part of formal logic or as the fundamentals of mathematics, now computers and formal languages can transcribe mathematical definitions, statements, and proofs in a machine-readable and machine-processable way so that a computer can verify a proof. Computer-assisted proofs are now generally accepted in the mainstream (at least concerning symbolic computations), a long time passed from the “shock” of the four-color theorem and other early examples in the 70s and 80s of the necessary role of computing in mathematics. Beyond using a computer for a specific calculation that helps in the course of a proof, formalized mathematics brings the possibility of verifying the whole chain of arguments and logical steps that prove the statement of a theorem from its hypothesis. The system and language Coq was used by Georges Gonthier to formalize the aforementioned four-color theorem in 2005 and the Feit-Thompson conjecture in 2012. More recently, the LEAN system has shown to be helpful in backing up mathematical proofs such as the condensed mathematics project by Peter Scholze in 2021, or the polynomial Freiman-Ruzsa conjecture by Tim Gowers, Terence Tao, and others in 2023.
Proponents of the “formalized mathematics revolution” dream of a future in which all research articles will be accompanied by a machine-readable counterpart that encodes the same statements and proofs as the human-readable part. At some point, AI systems could help translate human-to-machine. Then verification and peer-reviewing the validity of a result will become a trivial run of the code in a system, leaving human intervention to purely language clarity and style of speech matters. Some even speculate that when logical deduction techniques can be made machine-encoded, artificial intelligence systems can be trained to optimize, suggest, or generate new results in collaboration with human mathematicians.
Whether those formalized languages remain a niche tool or become a widespread practice for mathematicians at large, and whether mathematical research will one day be assisted by artificial systems, are open questions to be seen in the next few decades.




AI Video Series
NFDI4DS produced the video series "Conversations on AI Ethics". Each of the ten episodes features a specific aspect of AI, interviewing well-known experts in the field. All episodes are available on YouTube and the TIB AV Portal.
More information:
BERD Research Symposium
The event is scheduled for June 2024 and encompasses conference-style sessions and a young researchers' colloquium, fostering collaboration and exchange of information in research in business, economics, and social science. The event's primary focus is the collection, pre-processing, and analysis of unstructured data such as image, text, or video data. Registration deadline:
May 1st, 2024.
More information:
- in English

Call for Proposals
You may apply for funding to process and secure research data to continuously expand the offerings of data and services provided by Text+ and make them available to the research community in the long term. Multiple projects between EUR 35,000 and EUR 65,000 can be funded. Additionally, an overhead of 22% is granted on the project sum. The project duration is tied to the calendar year 2025; thus, it is a maximum of 12 months. Application deadline: March 31, 2024
More information:
In this short video "Treffen sich 27 Akronyme, oder: WTF ist NFDI?" Sandra Zänkert explains the idea behind NFDI, its current state and some challenges on the road to FAIR science.
The paper "Computational reproducibility of Jupyter notebooks from biomedical publications" by Sheeba Samuel and Daniel Mietchen examines large-scale reproducibility of Jupyter notebooks associated with published papers. The corpus here is from biomedicine, but much of the methodology also applies to other domains.
The Freakonomics Radio is a popular English language Podcast that recently published an interesting two-part series on academic fraud.
The paper "The Field-Specificity of Open Data Practices", by Theresa Velden, Anastasiia Tcypina provides quantitative evidence of differences in data practices and the public sharing of research data at a granularity of field-specificity rarely reported in open data surveys.
When your open-source project starts getting contributors, it can feel great! But as a project grows, contributors can neglect to document everything. In this situation, the article "Building a community of open-source documentation contributors" by Jared Bhatti and Zachary Sarah Corleissen may help you.


{kind=link}

Data Management: From Theory to Practice
In previous MaRDI newsletter articles, we discussed what is Mathematical Research Data, the guiding principles that define proper, good quality research data (the FAIR principles), and why as a researcher you should care about your data. It is time now to raise the question of how to properly curate your research data in practice.
Research Data Management (RDM) refers to all handling of data related to a research project. It includes a planning phase (written as a formal RDM plan and included in an application for funding agencies), an ongoing data curation and plan revision during the project, and an archival phase at the conclusion of the project.
In this article, we will survey the main points to consider for proper data management. There are, however, more comprehensive and detailed guides that you can use to create your own RDM plan. The MaRDI community has written a report on Research-data management planning in the German mathematical community, and a whitepaper (Research Data Management Planning in Mathematics) that will be helpful in the context of mathematics. You can also get useful resources from other NFDI consortia, such as the FAIRmat Guide to writing a Research Data Management Plan.
Writing an RDM plan
An RDM plan is a document that describes how you and your team will handle the research data associated with your research project. This document is a helpful reference for the researchers on how to fulfill data management requirements. It is a standard requirement nowadays from many funding agencies on their application regulations for projects.
There are several standard key points to consider in an RDM plan. These points were developed by Science Europe and have been adopted across agencies internationally. You can check the evaluation criteria for each point that evaluators are likely to use when reviewing your application. In Germany, the key requirements are given by the German Research Foundation, the DFG.
Data description
First and foremost, you need to know the type of data you will be handling. Start by describing the types of data involved in your project (experimental records, simulations, software code…). It is a good idea to separate data by its provenance: internal data is data generated within the project, whereas external data is data used for the project that is generated elsewhere. When recording internal data, specify the means of data generation (by measuring instruments in the laboratory, by software simulation, written by a researcher…). As for the documentation of external data, include details of any interface/compatibility layer used (for instance format conversions).
Workflows of data are in itself a type of data. If you process data in a complex way (combining data from different sources, involving several steps, using different tools and methods…) the process in itself, the workflow, is something that should be properly documented and treated as research data.
Plan in advance the file formats required for recording, the necessary toolchains, and other aspects that affect interoperability. Prioritize the use of open formats and standards (if you need to use proprietary formats, consider saving both the proprietary and an exported copy to an open format). Finally, estimate the amount of data you will collect, and any other practical needs that you or anyone using the data will require. As you cannot foresee in detail the various data requirements (for instance, you may not know the specific software tools necessary to solve your problem), your RDM plan should be updated at a later stage if the type, volume, or characteristics of your data change significantly.
In mathematics, it is likely that you will generate some text and pdf files for your texts, with graphics from different sources. If your bibliographies grow above a hundred references, you may use separate BibTeX files (.bib) that you can re-use across publications, and constitute a usually overlooked piece of research data.
If your project involves computations, you will have scripts, notebooks, or code files that serve as input for your computation engine. Your system will require a toolchain to work, for instance, a particular installation of Singular, OSCAR, MatLab, a C compiler…, together with some installed libraries and dependencies. You may use an IDE or a particular text editor (while that may seem a personal choice not relevant for other users, it is in fact quite useful to know how some software was developed in practice). This toolchain is also a piece of research data that needs to be curated. You may have output files that require documentation, even if they can be recreated from the inputs. If your project involves third-party databases, these should be properly referenced and sourced.
Documentation and data quality
Data must be accompanied by rich metadata that describes it. Your documentation plan should state the metadata you need to collect, and explain how it will stay attached to the data. Once you have a description of your data, you need to organize it. Create a structure that will accommodate all the generated data. The structure can include some hierarchy in your filesystem, conventions for naming files, or another systematic way to find and identify your data easily. Do not call your files “code.sing”, “paper.tex” or “example3_revised 4 - FINAL2.txt”, instead use meaningful names such as “find_eigenvalues.nb” and start your document with comments explaining what this file is, the author, language, date, references to theory, how to run it, and any other useful information.
Good documentation will be a crucial step in enabling the reusability of the data. If you are developing a software library, you need to document the functions, APIs, and other parts of the software, including references to the theoretical sources that your algorithms are based on. If you are curating a database or a classification of mathematical objects, you need to document the meaning of fields in your tables, the formulae for derived values, etc. If parts of the data can be re-generated (for example, as a result of a simulation), you should describe how to do so, and differentiate clearly between source data and automatically generated data.
Data quality refers to the FAIRness of the data, which needs to be checked and addressed during the implementation phase. At the planning stage, you can provide metrics to evaluate data quality, and provide quality control mechanisms. For instance, checking the integrity of data periodically, and testing whether the whole toolchain can be installed and executed successfully. You can plan a contingency in case some tools become obsolete or unavailable.
Storage and archiving
Storing and archiving research data is not a trivial matter and should be planned carefully. On one hand, it requires security against data loss (or data break in case of sensitive data), and on the other hand, it needs to be accessible to all the researchers involved, in a practical way.
Your storage strategy should take into account the amount of data (large volumes of data are more difficult to move and preserve), its persistence (experiments are recorded usually only once, whereas an article or computer code is rewritten again and again with improvements), the number of people needing write access, or the sensitivity of the data (for instance, data related to people can have private information that needs to be anonymized and access-controlled, whereas non-sensitive data can be put in public repositories).
Backup plans should include keeping several copies of the data, in different physical locations and different media. Important key files (e.g. indices or tables listing contents of other files) should be specially protected and backed up. Synchronizing and keeping up versions of data is also important to avoid unorganized data. If your team has several people needing write access to the same data, you need appropriate tools to avoid conflicting versions, such as online multi-user editors (e.g. Overleaf, Nextcloud/collabora, Google docs…), or version control systems. Remember to always backup a local copy and not keep your only copy on the cloud. A good scientific practice is to keep your storage for at least 10 years after publication or project completion.
Legal and ethical obligations
It is important to be safe with the legal obligations associated with data, and related ethical considerations that may arise.
All data should be associated with an author or an owner, who has the right to decide a license and control its access, usage, and other legal prerogatives. Intellectual property and copyright may apply to some data, like patents, software, commercial products, or publications. Intellectual property protects ideas (but not facts of nature), while copyright protects an expression of an idea. In mathematics, a theorem cannot be protected by intellectual property (since it is a fact of nature), while an algorithm for a practical purpose or its implementation in software could be protected by it. The text of a scientific article is generally protected by copyright, even if the ideas contained therein are free. If the copyright of your written texts is to be transferred to a publisher (as it is standard practice), you should state the conditions that are acceptable within your project and your publication strategy (see next section).
Sensitive data (e.g. medical records, personal information…) require a specific data handling policy with special attention to data protection and access.
In all cases, you should include an appropriate license note, after evaluating all implications. For open licenses, you should prefer standard licenses (for instance Creative Commons or free/open software licenses) instead of crafting your own licenses or adding/removing clauses, which can lead to license incompatibilities and encumber its reusability. See our article on Reusability.
Data exchange
Data exchange involves an integration of the project and its data with the community. Data should be readily found, accessed, operated, and reused by anyone with a legitimate interest in it. In practice, this data exchange will involve a data preservation strategy for the long-term (archiving), as well as a dissemination strategy (using community standards to share data).
While the storage and archiving section above concerns mainly data security and preservation, this data exchange section focuses on the FAIRness (and specially the accessibility) of the data and its exchange within the community. Naturally, both topics overlap. FAIRness of data is heavily affected by the FAIRness of the repositories or hosting solutions that store and make this data accessible. Look for FAIR and reliable repositories in your domain that can host online versions of your data during the implementation of the project and also act as a long-term archiving solution.
In this section, you can include the publication strategy for your research articles. This includes, whether you plan to publish pre-prints or final articles in free repositories (like arXiv), or whether you consider publishing only in open-access journals, etc. Though there are comprehensive catalogs for literature in mathematical research (zbMATH open, MathSciNet), it is always good to ensure that your publications are findable and accessible. For other types of data, you should carefully consider their dissemination, and ensure that your data is listed in relevant catalogs.
Responsibilities
All research data needs someone to take care of it. A person (or a team) must take responsibility for the research data in the project. This responsibility may be that of the owner/author, or someone else. A data steward can be appointed to help with the technical aspects of data management. There can also be teams designated with different responsibilities during different phases of the project (planning, implementation, archiving), but they should be public and well defined, and serve as a contact point during and after the project.
In case the data is meant to be static (no changes in the future), then the responsible person is only answerable for what has been published. If, on the other hand, the data is expected to grow in the future (for instance a growing classification of mathematical objects), a maintainer should be appointed for the future, to take care of advances in the field and incorporate the data to its appropriate place. In case the maintainer can no longer take care of that role, the position should be transferred to another suitable person/team, for as long as the project needs a maintenance team.
MaRDI RDM consulting
We can offer a couple of examples of RDM plans from MaRDI, developed in the context of mathematics by MaRDI members. First, for a project applying statistical analysis to datasets containing student records for a study in didactics [RDMP1]. Second, for a project that develops algorithms and software with applications in robotics [RDMP2]. These are prototypes we prepared along with RDM experts from Leipzig university for mathematics projects planned by our researchers. We handed these out as examples to the community at the DMV annual meetings in 2022 and 2023.
MaRDI can offer consulting services for math projects that need help with creating their own RDM plan, or just figuring out the necessary infrastructure and best practices for a FAIR RDM. You can contact the MaRDI Help Desk for more information.
Tools for keeping your RDM up
There are some existing tools to help researchers plan and fulfill an RDM plan. These can be used in small or individual projects, though they are meant for large projects involving many researchers. We will briefly discuss Research Data Management Organizer (RDMO), a web-based service widely used in German research institutions.
RDMO is a free open-source software developed as a DFG project, meant to run as a web service in your institution's infrastructure. Normally, a data manager (data steward) will play an administrator’s role and install the RDMO software in a server with access to the institution researchers. The data manager will create questionnaires for handling the data of a specific project. That questionnaire will be available in an online form that researchers can fill-in for each piece of data that they create or gather. By analyzing this questionnaire, a standardized file can be exported, that serves as metadata of the described data. Template questionnaires are available, so that all relevant information is included (e.g. the DFG guidelines). The questionnaires can also be used to generate a standardized RDM plan for the project. No data is actually stored or handled in the RDMO platform, RDMO and other RDM tools only handle metadata and help with organization. You still need to store and structure your research data, ensure data quality, apply licenses, manage data exchange, etc. These tasks are not automated by any RDM tool and you are still in charge of implementing your RDM plan.
Some institutions will require you to use this platform to prepare RDM plans for their research projects. Such a case is Math+ excellence cluster at Zuse Institute Berlin. A version of the questionnaire that ZIB researchers use is available in [Quest1] (also published here in XML format; the actual RDMO instance is only available to ZIB users). Using such a system reduces the possibility of unintended omissions, ensures compatibility with the guidelines of their funding agency (DFG), and uniformizes RDM plans across different projects.
MaRDI is also actively using RDMO as part of its task area devoted to interdisciplinary workflows. Workflows are important research data for projects involving researchers from different disciplines, making its management particularly challenging. MaRDI has prepared an RDMO questionnaire that can describe workflows in a MaRDI standard way, you can have a look in [Quest2] (also published here in XML format). Additionally, MaRDI is developing MaRDMO, an RDMO plug-in that can be installed on the instance of RDMO you use (a live demo will be soon available). This plug-in will add the feature of exporting the documented workflow metadata directly to the MaRDI knowledge graph, and make it findable and accessible through the MaRDI portal. This will provide a streamlined method to populate the MaRDI knowledge graph directly from the researchers, with the same tool they used to create an RDM plan and manage their RD metadata.






Workshop on RDM in Modelling in Computer Science
This NFIDxCS workshop is a base for discussing systematic approaches to dealing with research data. The workshop aimed to gather individuals willing to contribute to the handling of research data management. The result will be a manifesto for research data management in modeling research (in Computer Science). Date: March 11, 2024, submission deadline: January 8, 2024.
More information:
- in English

Data Management Plan Tool
The German Federation for Biological Data (GFBio) offers a Data Management Plan (DMP) Tool. It will help you find answers to important questions about the data management of your project, and create a structured PDF file from your entries. You can also get free personal DMP support from their experts.
More information:
- in English
Mailing list “Math and Data Forum”
The MaRDI mailing list “Math and Data Forum” offers news and insights into the realm of mathematical research data as well as a discussion forum for research data management practices and services in mathematics.
More information:

Special ITIT Issue Data Science and AI within the NFDI
Data Science and AI is an interdisciplinary field that is important for many NFDI consortia. This special issue of the journal "it - Information Technology" will focus on recent developments in Data Science and AI in the different consortia. Submission deadline: January 31, 2024.
More information:
- in English
The whitepaper Research Data Management Planning in Mathematics by the MaRDI consortium aims to guide mathematicians and researchers from related disciplines who create research data management (RDM) plans. It highlights the benefits and opportunities of RDM in mathematics and interdisciplinary studies, showcases examples of diverse Math research data and suggests technical solutions that meet the requirements of funding agencies with specific examples.
This guide to writing a Research Data Management Plan by FAIRmat provides you with comprehensive information and practical tips specific to the fields of condensed-matter physics and materials science on creating a data management plan (DMP) that meets the DFG requirements and aligns your research with the FAIR data principles, the DFG code of conduct, and the EU open science policy.
The DFG guidelines on Research Data Management (2021) include this Checklist for planning and description of handling of research data in research projects.
The EMS article "Research-data management planning in the German mathematical community" by Tobias Boege and many other MaRDIans discusses the notion of research data for the field of mathematics and reports on the status quo of research-data management and planning.
Science Europe offers a practical Guide to the International Alignment of Research Data Management. Find the Extended Edition here.
The review Making Mathematical Research Data FAIR: A Technology Overview by Tim Conrad and several other MaRDIans aims to perform a technology review on existing data repositories/portals with a focus on mathematical research data.
- MaRDIan Daniel Mietchen was invited to give an NFDI InfraTalk on Scholia - an open-source profiling tool to explore scholarly knowledge via open data from Wikidata. He is one of the core developers of Scholia, which provides dozens of profile types, each composed of multiple panels that render pertinent information based on a predefined SPARQL query that is parametrized via the Wikidata identifier of the concept to be profiled. It also facilitates collaborative curation of this information in Wikidata. Luckily, the talk was recorded and is available on YouTube for you to watch.
In the rather short article Share and share alike: Top 5 reasons to share your research data! Isabel Chadwick convinces you to share your data by highlighting some key benefits.


"Yesterday at the Math Bazaar exchanging recent research data..."
{kind=link}

Is there Math Data out there?
“Mathematics is the queen and servant of sciences”, according to a quote by Carl F. Gauss. This opinion of Gauss can be a source of philosophical discussions. Is Mathematics even a science? Why does it play a special role? Connecting these questions to our concerns, what is the relationship between research data and these philosophical questions? We cannot arrive at a conclusion in this short article, but it is a good starting point to discuss the mindset (the philosophy, if you wish) that should be adopted regarding research data in mathematical science.
A wide agreement is that a science is any form of study that follows the scientific method: observation, formulation of hypotheses, experimental verification, extraction of conclusions, and back to observation. In most sciences (natural sciences and, to a great extent, also social sciences), observation requires gathering data from nature in the form of empirical records. In contrast, in pure mathematics observations can be made simply by reflection on known theory and logic. In natural sciences, nature is the ultimate judge of the validity or invalidity of a theory. This experimental verification also requires gathering research data in the form of empirical records that support or refute a hypothesis. In contrast, in mathematics, experimental verification is substituted by formal proofs. Such characteristics have prompted some philosophers to claim that mathematics is not really a science, but a meta-science because it does not rely on empirical data. More pragmatically, it can tempt some researchers and mathematicians to say that (at least, pure) mathematics does not use research data. But as you will guess, in the Mathematical Research Data Initiative (MaRDI), we advocate for quite the opposite view.
Firstly, some parts of mathematics do use experimental data extensively. Statistics (and probability) is the branch of mathematics for analyzing large collections of empirical records. Numerical methods are practical tools to perform computations in experimental data. This is the case for pure mathematics as well, where we can build lists of records (prime numbers, polytopes, groups…) that are somewhat experimental.
Secondly, research data are not only empirical records. Data are any raw piece of information upon which we can build knowledge (we discussed the difference between data, information, and knowledge in the previous newsletter). When we talk about research data, we mean any piece of information that researchers can use to build new knowledge in the scientific domain in question, mathematics in this case. As such, articles and books are pieces of data. More precisely, theorems, proofs, formulas, and explanations are individual pieces of data. They have traditionally been bundled into articles and books, and stored in paper, but nowadays are largely available in digital form and accessible through computerized means.
Types of data
In modern mathematical research, we can find many types of data:
Documents (articles, books) and their constituent parts (theorems, proofs, formulas…) are data. Treating mathematical texts as data (and not only as mere containers where one deposits ideas in written form) recognizes that mathematical texts deserve the same treatment as other forms of structured data. In particular, FAIR principles and data management plans also apply to texts.
Literature references are data. Although bibliographic references are part of mathematical documents, we mention them separately because references are structured data. There is a defined set of fields, (such as author, title, publisher…), there are standard formats (e.g. bibTeX), and there are databases of mathematical references (e.g. zbMATH, MathSciNet,...). This makes bibliographic references one of the most curated type of research data (especially in Mathematics) .
Formalized mathematics is data. Languages that implement formal logic like Coq, HOL, Isabelle, Lean, Mizar, etc, are a structured version of the (unstructured) mathematical texts that we just mentioned. They contain proofs verifiable by software and are playing an increasingly vital role in mathematics. Data curation is essential to keep those formalizations useful and bound to their human-readable counterparts.
Software is data. From small scripts that help in a particular problem to wide libraries that integrate into larger frameworks (Sage, Mathematica, MATLAB…). Notebooks (Jupyter,...) are a form of research data that mix text explanations and interactive prompts, so they need to be handled as both documents and software.
Collections of objects are data. Classifications play a major role in mathematics. Either gathered by hand or produced algorithmically, the result can be a pivotal point on which many other works will derive from. Although this output result of a classification can have more applications than the process to arrive at it, it is essential that both input algorithm (or manual process) and the output classification are clearly documented, so that the classification can be verified and reproduced independently, apart from being reused in further projects.
Visualizations and examples are data. Examples and visual realizations of mathematical objects (including images, animations, and other types of graphics) can be very intricate and have an enormous value for understanding and developing a theory. Although examples and visualizations can be omitted in more spartan literature, if provided, they deserve a full research data curation as other research data essential to logical proofs.
Empirical records are data. Of course, raw collection of natural information, intended to be processed to extract knowledge of the data itself, or from the statistical method, are data that need special tools to handle. This applies to statistical databases, but also to machine learning models that require vast amounts of training data.
Simulations are data. Simulations are lists of records not measured from the outside world, but generated from a program. This is usually a representation of a state of a system, including possibly some discretizations and simplifications of reality in the modeling process. As with collections, this output simulation data is as necessary as the input source code that generates it. Simulation data is what allows us to extract conclusions, whereas the reproducibility verification requires that the processing input-to-output be performed by a third party, allowing the recognition of flaws or errors in either the input or the output, or allowing for the rerun of the simulation with different parameters.
Workflow documentations are data. More general than simulations, workflows involve several steps of data acquisition, data processing, data analysis, and extraction of conclusions in many scientific researches. An overview of the process is in itself a valuable piece of data, as it gives insights into the interplay of the different parts. A numerical algorithm can be individually robust and performant, but it may not be the best fit for the task at hand. We can only spot such issues when we have a good overview of the entire process.
The building of mathematics
One key difference between mathematics and other sciences is the existence of proofs. Once a result is proven, it is true forever, as it cannot be overruled by new evidence. The Pythagorean theorem, for instance, is today as valid and useful as it was in the times of Pythagoras (or even in the earlier times of ancient Babylonians and Egyptians, who knew and used it. However, the Greeks invented the concept of proof, turning mathematics from a practice into a science). The Book of Elements by Euclid, written circa 300 BC, one of the most relevant books in the history of mathematics and mankind, perfectly represents the idea that mathematics is a building, or a network, in which each block is built on top of others, in a chain starting with some predetermined axioms. The image shows the dependency graph of propositions in Book I of the Elements.
Dependency graph of propositions in Book I of Euclid’s Elements (source). Proposition I.47 is the Pythagorean theorem.




image credit: NFDI-MatWerk

image credit: Heike Fliegl (FIZ)
Math Meets Information Specialists, October 09 - 11, 2023, MPI MiS, Leipzig
MaRDI invites information specialists, librarians, data stewards, and mathematicians to discuss mathematical research data, present their own ideas and services, and make new connections in a three-day noon-to-noon workshop with talks, hands-on sessions, and a barcamp. The workshop will be held in German.
More information:
- in German

Data-Driven Materials Informatics, March 4 - May 24, 2024
The aim of this long program at IMSI is to bring together a diverse scientific audience, both between scientific fields (physical sciences, materials sciences, biophysics, etc.) and within mathematics (mathematical modeling, numerical analysis, statistics, data analysis, etc.), to make progress on key questions of materials informatics.
More information:
- in English
RDM with LinkAhead, September 29, 2023, online
At the NFDI4Chem Stammtisch, the research data management software LinkAhead will be introduced. This agile, open-source software toolbox enables professional data management in research where other approaches are too rigid and inflexible. It will make your data findable and reusable.
More information:
NFDI Code of Conduct
The Consortial assembly, comprising the speakers of each consortium, voted on 27 June 2023 to adopt the code of conduct for the NFDI. This Code of Conduct is intended to provide a binding framework for effective collaboration within the NFDI association.
More information:
- in German
- A a generic JSON based file format which is suitable for computations in computer algebra is described in the paper A FAIR File Format for Mathematical Software by Antony Della Vecchia, Michael Joswig, and Benjamin Lorenz. This file format is implemented in the computer algebra system OSCAR, but the paper also indicates how it can be used in a different context.
- To understand our world, we classify things. A famous example is the periodic table of elements, which describes the properties of all known chemical elements and classifies the building blocks we use in physics, chemistry, and biology. In mathematics, and algebraic geometry in particular, there are many instances of similar periodic tables, describing fundamental classification results. In his article, The Periodic Tables of Algebraic Geometry, Pieter Belmans invites you on a tour of some of these results. It appeared within the series 'Snapshots of modern mathematics from Oberwolfach'.
- Play with the educational tool Classified graphs. With this open-source web app you can draw any graph, or select one from a collection, and then compute a few invariants, such as the adjacency determinant. In the Identify mode, you are challenged to find out which of the graphs in the collection is shown as a target. The tool is part of Pieter Belmans's project Classified maths.
- In each episode of the podcast "Mathematical Objects", Katie Steckles and Peter Rowlett chat about some aspect of mathematics using a mathematical object as inspiration. The podcast is also available on YouTube.
- Proceedings of the Conference on Research Data Infrastructure (CoRDI):
https://www.tib-op.org/ojs/index.php/CoRDI/issue/view/12
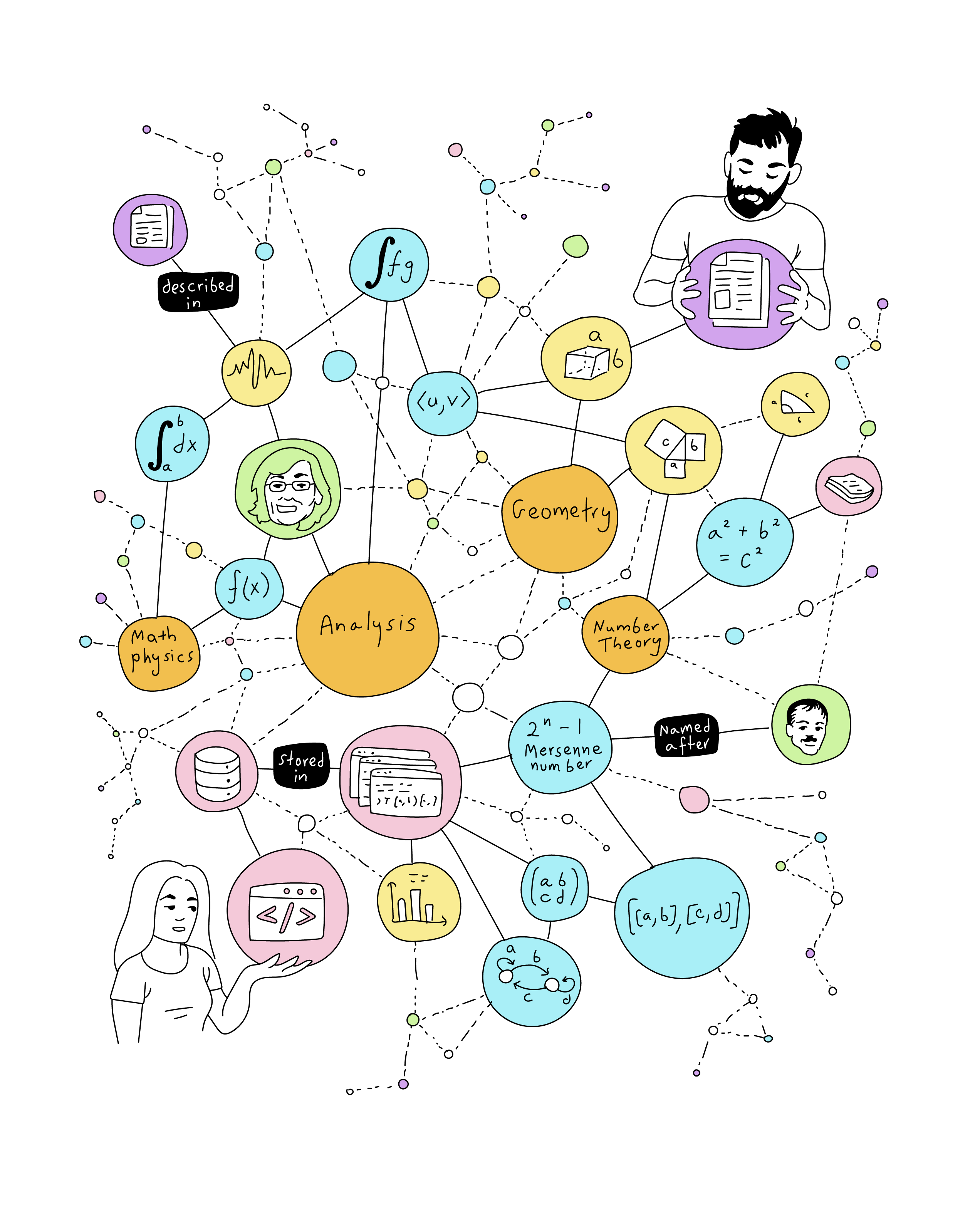{kind=link}
The knowledge ladder
We are not sure exactly how humans store knowledge in their brains, but we certainly pack concepts into units, and then relate those conceptual units together. For example, if asked to list animals, nobody remembers an alphabetical list (unless you explicitly train yourself to remember such a list). Instead, you start the list with something familiar, like a dog, then you recall that dog is a pet animal, and then you list other pet animals like cat or canary. Then you recall that canary is a bird, and then you list other birds, like eagle, falcon, owl… when you run out of birds, you recall that birds fly in the air, which is one environment medium. Another environment medium is water, and this prompts you to start listing fishes and sea animals. This suggests that we can represent human knowledge in the form of a mathematical graph: concepts are nodes, and relationships are edges. This structure is also ingrained in language, which is the way humans communicate and store knowledge. All languages in the world, across all cultures, have nouns, verbs, or adjectives, and establish relationships through sentences. Almost every language organizes sentences in a subject-verb-object pattern (or any permutations: SVO, SOV, VSO, etc). The subject and the object are typically nouns or pronouns, the verb is often a relationship. A sentence like “my mother is a teacher” encodes the following knowledge: the person “my mother” is a node 1, “teacher” is a node 2, and “has as a job” is a relational edge from node 1 to node 2. Also, there is a node 3, the person “me”, and a relationship “is the mother of” from node 1 to node 3, (which implies a reciprocal relationship “is a child of” from node 3 to node 1).
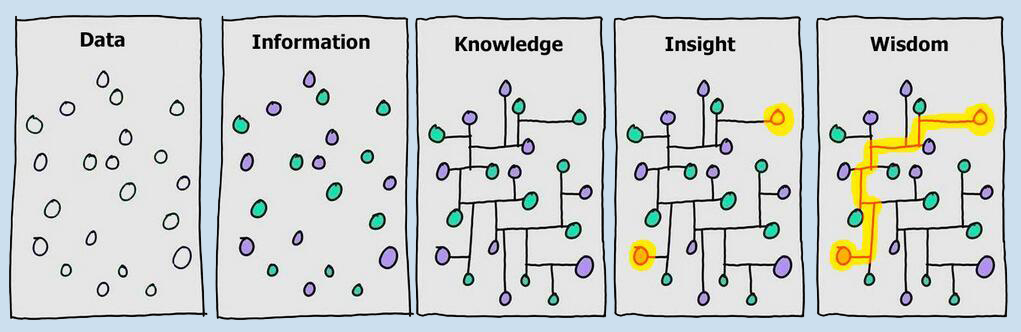
David Somerville / Hugh McLeod
informationversusknowledge-blog.tumblr.com/
A Google search of “Agatha Christie” in June 2023. It offers much more than just links to webs containing the string “Agatha Christie”. Those boxes “About”, “People also search for”, “People also ask”... are powered by Google’s knowledge graph.
Wikipedia (human-readable, non-structured)
Wikidata (machine-readable, structured)
One of the mottos of MaRDI is “Your Math is Data”. Indeed, from an information theory perspective, all mathematical results (theorems, proofs, formulas, examples, classifications) are data, and some mathematicians also use experimental or computational data (statistical datasets, algorithms, computer code…). MaRDI intends to create the tools, the infrastructure, and the cultural shift to manage and use all research data efficiently. In order to climb up the “knowledge ladder” from Data to Information and Knowledge, the Data needs to be structured, and knowledge graphs are one excellent tool for that goal.
AlgoData
Several initiatives within MaRDI are based on knowledge graphs. A first example is AlgoData (requires MaRDI / ORCID credentials), a knowledge graph of numerical algorithms. In this KG, the main entities (nodes) are algorithms that solve particular problems (such as linear systems of equations or integrate differential equations). Other entities in the graph are supporting information for the algorithms, such as articles, software (code), or benchmarks. For example, we want to encode that algorithm 1 solves problem X, it is described in article Y, it is implemented on software Z, and it scores p points in benchmark W. A use case would be querying for algorithms that solve a particular type of problem, comparing the candidates using certain benchmarks, and retrieving the code to be used (ideally, being interoperable with your system setup).
AlgoData has a well-defined ontology. An ontology (from the Greek, loosely, “study or discourse of the things that exist”) is the set of concepts relevant to your domain. For instance, in an e-commerce site, “article”, “client”, “shopping cart”, or “payment method” are concepts that need to be defined, and included in the implementation of the e-commerce platform. For knowledge graphs, the list would include all types of nodes, and all labels for the edges and other properties. In general-purpose knowledge graphs, such as Wikidata, the ontology is huge, and for practical purposes the user (human or machine) relies on search/suggestion algorithms to identify the property that fits the most to their intention. In contrast, for specific-purpose knowledge graphs, such as AlgoData, a reduced and well-defined ontology is possible, as it simplifies the overall structure and search mechanisms.
The ontology of AlgoData (as of June 2023, under development) is the following:
Classes:
Algorithm, Benchmark, Identifiable, Problem, Publication, Realization, Software.
Object Properties:
analyzes, applies, documents, has component, has subclass, implements, instantiates, invents, is analyzed in, is applied in, is component of, is documented in, is implemented by, is instance of, is invented in, is related to, is solved by, is studied in, is subclass of, is surveyed in, is tested by, is used in, solves, specializedBy, specializes, studies, surveys, tests, uses.
Data Properties:
has category, has identifier.
We can display this ontology as a graph,

The ontology of AlgoData (version 0.1, June 2023)

- Knowledge ladder: Steps on which information can be classified, from the rawest to the more structured and useful. Depending on the authors, these steps can be enumerated as Data, Information, Knowledge, Insight, Wisdom.
- Data: raw values collected from measurements.
- Information: Data tagged with its meaning.
- Knowledge: Pieces of information connected together with causal or other relationships.
- Knowledge base: A set of resources (databases, dictionaries…) that represent Knowledge (as in the previous definition).
- Knowledge graph: A knowledge base organized in the form of a mathematical graph.
- Insight: Ability to identify relevant information from a knowledge base.
- Wisdom: Ability to find (or create) connections between information points, using existing or new knowledge relationships.
- Ontology: Set of all the terms and relationships relevant to describe your domain of study. In a knowledge graph, the types of nodes and edges that exist, with all their possible labels.
- RDF (Resource Description Framework): A web standard to describe graphs as triples (subject - predicate - object).
- SPARQL (Simple Protocol And RDF Query Language): A language to send queries (information retrieval/manipulation requests) to graphs in RDF format.
- Wikipedia: a multi-language online encyclopedia based on articles (non-structured human-readable text).
- Wikidata: an all-purpose knowledge graph intended to host data relevant to multiple Wikipedias. As a byproduct, it has become a tool to develop the semantic web, and it acts as a glue between many diverse knowledge graphs.
- Semantic web: a proposed extension of the web in which the content of a website (its meaning, not just the text strings) is machine-readable, to improve search engines and data discovery.
- Mediawiki: the free and open-source software that runs Wikipedia, Wikidata, and also the MaRDI portal and knowledge graph.
- Scholia: A plug-in software for Mediawiki, to enhance visualization of data queries to a knowledge graph
- AlgoData: a knowledge graph for numerical algorithms, part of the MaRDI project.


MaRDI RDM Barcamp
MaRDI, supported by the Bielefeld Center for Data Science (BiCDaS) and the Competence Center for Research Data at Bielefeld University, will host a Barcamp on research-data management in mathematics on July 4th, 2023, at the Center for Interdisciplinary Research (ZiF) in Bielefeld.
More information:
- in English
Working group on Knowledge Graphs
The NFDI working group aims to promote the use of knowledge graphs in all NFDI consortia, to facilitate cross-domain data interlinking and federation following the FAIR principles, and to contribute to the joint development of tools and technologies that enable the transformation of structured and unstructured data into semantically reusable knowledge across different domains. You can sign up to the mailing list of the working group here.
Knowledge graphs in other NFDI consortia can be found for instance at the NFDI4Culture KG (for cultural heritage items) or at the BERD@NFDI KG (for business, economic, and related data items).
More information:
- in English
NFDI-MatWerk Conference
The 1st NFDI-MatWerk Conference to develop a common vision of digital transformation in materials science and engineering will take place from 27 - 29 June 2023 as a hybrid conference. You can still book your ticket for either on-site or online participation (online tickets are even free of charge).
More information:
- in English
Open Science Barcamp
The Barcamp is organized by the Leibniz Strategy Forum Open Science and Wikimedia Deutschland. It is scheduled for 21 September 2023 in Berlin and is open to everybody interested in discussing, learning more about, and sharing experiences on practices in Open Science.
More information:
- in English
- The department of computer science at Stanford University offers this graduate-level research seminar, which includes lectures on knowledge graph topics (e.g., data models, creation, inference, access) and invited lectures from prominent researchers and industry practitioners.
It is available as a 73-page pdf document, divided into chapters:
https://web.stanford.edu/~vinayc/kg/notes/KG_Notes_v1.pdf
and additionally as video playlist:
https://www.youtube.com/playlist?list=PLDhh0lALedc7LC_5wpi5gDnPRnu1GSyRG - Video lecture on knowledge graphs by Prof. Dr. Harald Sack. It covers the topics of basic graph theory, centrality measures, and the importance of a node.
https://www.youtube.com/watch?v=TFT6siFBJkQ The Working Group (WG) Research Ethics of the German Data Forum (RatSWD) has set up the internet portal “Best Practice for Research Ethics”. It bundles information on the topic of research ethics and makes them accessible.
https://www.konsortswd.de/en/ratswd/best-practices-research-ethics/


{kind=link}

On the shoulders of giants
The famous quote from Newton: “If I have seen further, it is by standing on the shoulders of giants" usually refers to how science is built on top of previous knowledge, with researchers basing their results on the works of scientists who came before them. One could reframe it by saying that scientific knowledge is reusable. This is a fundamental principle in the scientific community: once a result is published, anyone can read it, learn how it was achieved, and then use it as a basis for further research. Reusing knowledge is also ingrained in the practice of scientific research as the basis of verifiability. In natural sciences, the scientific method demands that experimental data back your claims. In mathematical research, the logic construction demands mathematical proof of your claims. This means that for a good scientific practice, your results must be verifiable by other researchers, and this verification requires a reuse of not only the mental processes but also the data and tools used in the research.
Research data must be as reusable as the results and publications they support. From the perspective of modern, intensively data-driven science, this demand poses some challenges. Some barriers to reusability are technical, because of incompatibilities of standards or systems, and this problem is largely covered in the Interoperability principle of FAIR. But other problems such as poor documentation or legal barriers can be even bigger obstacles than technical inconveniences.
Reuse of research data is the ultimate goal of FAIR principles. The first three principles (Findable, Accessible, Interoperable) are necessary conditions for effective reuse of data. What we list here as “Reusability” requirements are all the remaining conditions, often more subjective or harder to evaluate, that appeal to the final goal of having a piece of research data embedded in a new chain of results.
To be precise, the Reusability principle requires data and metadata to be richly characterised with descriptors and attributes. Anyone potentially interested in reusing the data should easily find out if that data is useful for their purposes, how it can be used, how it was obtained, and any other practical concerns for reusing it. In particular, data and metadata should be:
- associated with detailed provenance
- released with a clear and accessible data usage license.
- broadly aligned with agreed community standards of its discipline.
Documentation
It is essential for researchers to acknowledge that the research data they generate is a first-class output of their scientific research and not only a private sandbox that helps them produce some public results. Hence, research data needs to be curated with reusability in mind, documenting all details (even some that might seem irrelevant or trivial to its authors) related to its source, scope, or use. In data management, we use the term “provenance” to describe the story and rationale behind that data. Why does it exist, what problem was it addressing, how it was gathered, transformed, stored, used… all this information might be relevant for a third party that first encounters the data and has to judge if it is relevant for themselves or not.
In experimental data, it is important to document exactly what was the purpose of the experiment, which protocol was followed to gather the data, who did the fieldwork (in case that contact information is needed), which variables were recorded, how the data is organized, which software was used, which version of the dataset it is, etc. As an antithesis of the ideal situation, imagine that you, as a researcher, find out about an article that uses some statistical data that you think you could reuse or that you want to look at as a referee. The data is easily available, and it is in a format that you can read. The data, however, is confusing. The fields on the tables have cryptic names such as “rgt5” and “avgB” that are not defined anywhere, leaving you to guess their meaning. Units of the measures are missing. Some registries are marked as “invalid” without any explanation of the reason and without making clear whether those registries were used or not on calculations. Derived data is calculated from a formula, but the implementation in the spreadsheet is slightly but significantly different than the formula in the article. If you re-run the code, the results are thus a bit different from those stated in the article. At some point, you try to contact the authors, but the contact data is outdated, or it is unclear who of several authors can help with the data (you can picture such a scene in this animated short video). Note that in this scenario we describe, the research data might have been perfectly Findable, Accessible and technically good and Interoperable, but without attention to those Reusable requirements, the whole purpose of FAIR data is defeated.
In computer-code data, documentation and good community development practices are non-trivial issues the industry has been addressing for a long time. Communities of programmers concerned by these problems have developed tools and protocols that solve, mitigate, or help manage these issues. Ideally, scientists working on scientific computing should learn and follow those good practices for code management. For instance, package managers for standard libraries, version control systems, continuous integration schemes, automated testing, etc., are standard techniques in the computer industry. While not using any of these techniques and just releasing source code in zip files might not break F-A-I principles, it will make reuse and community development much more difficult.
Documenting algorithms is especially important. Algorithms frequently use tricks, constants that get hard-coded, code patterns that come from standard recipes, parts that handle exceptional cases… Most often, even a very well-commented code is not enough to understand the algorithm, and a scientific paper is published to explain how the algorithm works. The risk is having a mismatch between the article that explains the algorithm, and the released production-ready code that implements it. If the code implements something similar but not exactly what is described in the article, there is a gap where mistakes can enter. Having a close integration between the paper and the code is crucial to prevent the newcomer from having to rework how the described algorithm translates into code.
Verifiability
As we introduced above, independent verification is a pillar of scientific research, and verification cannot happen without reusability of all necessary research data. MaRDI puts a special effort into enabling verification of data-driven mathematical results, by building FAIR tools and exchange platforms for the fields of computer algebra, numerical analysis, and statistics and machine learning.
An interesting example arises in computer algebra research. In that field, output results are often as valuable by themselves as the program that produced them. For instance, classifications and lists are valuable by themselves (see for example the LMFDB or MathDB sites for some classification projects). Once that list is found, it can be stored and reused for other purposes without any need to revisit the algorithm that produced such a list. Hence, the focus is normally on reusability of the output, but forgetting the reusability of the sources. This neglects to describe the provenance of the data, how it was created, which techniques were used to find it. This entails serious risks. Firstly, it is essential to verify that the list is correct (since a lot of work will be carried out assuming it is). Secondly, it is often the case that later research needs a slight variation of the list offered in the first place, so researchers need to modify parameters or characteristics of the algorithm to create a modified list.
In the case of numerical analysis, the output algorithms are usually focused on user reusability, often in the form of computing packages or libraries. However, several different algorithms may compete for accuracy, speed, hardware requirements, etc., so the “verification” process gets replaced by a series of benchmarks that can rate an algorithm in different categories and verify its performance. We have described, in the previous newsletter, how MaRDI would like to make numerical algorithms easier to reuse and benchmark them in different environments.
As for statistical data, our Interoperability issue of the newsletter describes how MaRDI curates datasets with “ground truths,” known facts that we know for sure independently from the data, that allow for the validation of new statistical tools to be applied to the data. In this case, re-using these new statistical tools on new studies increases the corpus of cases where the tool has been successfully used, making each reuse a part of the validation process.
Licenses
We also discussed licenses in our Accessibility issue. Let’s recall that FAIR principles do not prescribe free / open licenses, although those licenses are the best way to allow unrestricted reusability. However, FAIR principles do require a clear statement of the license that applies, be it restrictive or permissive.
Even within free/open licenses, the choice is wide and tricky. In software, open source licenses (e.g. MIT, Apache licenses) refer to the fact that the source code must be provided to the user. Those are amongst the most permissive because with the code one can study, run, or modify it. In contrast, free software licenses (e.g. GPL) carry some restrictions and an ethical/ideological load. For instance, many free licenses include copyleft, which means that any derived work must keep the same license, effectively preventing a company to bundle this software in a proprietary package that is not free software.
In creative works (texts, images…), the Creative Commons licenses are the standard legal tool to explicitly allow redistribution of works. There are several variants, ranging from almost no restrictions (CC0 / Public domain), to including clauses for attribution (CC-BY, attribution), sharing with the same license (CC-SA, share alike), or restricting commercial use (CC-NC, non-commercial) or derivative works (CC-ND, non-derivative), and any compatible combination. For databases, the Open Database License (ODbL) is a widely used open license, along with CC.
The following diagram shows how you can determine which CC license would be appropriate for you to use:

Diagram on Intellectual Property and Creative Commons by MaRDI,
licensed under CC BY-NC-ND



Conference on Research Data Infrastructure
The Conference will take place September 12th – 14th, 2023, in Karlsruhe (Germany). There will be disciplinary tracks and cross-disciplinary tracks.
Abstract submissions deadline: April 21, 2023
More information:
- in English
IceCube - Neutrinos in Deep Ice
This code competition aims to identify which direction neutrinos detected by the IceCube neutrino observatory came from. PUNCH4NFDI is focused on particle, astro-, astroparticle, hadron, and nuclear physics, and is supporting this ML challenge.
Deadline: April 23, 2023
More Information:
- in English
Open Science Radio
Get an overview of all NFDI consortia funded to date, and gain an insight into the development of the NFDI, its organizational structure, and goals in the 2-hour Open Science Radio episode interviewing Prof. Dr. York Sure-Vetter, the current director of the NFDI.
Listen:
- in English
The DMV, in cooperation with the KIT library, maintains a free self-study course on good scientific practice in mathematics, including notes on the FAIR principles. (Register here to subscribe to the free course.)
Edmund Weitz of the University of Hamburg recorded an entertaining chat about mathematics with ChatGPT (in German).
Remember our interview about accessibility with Johan Commelin in the second MaRDI Newsletter? The Xena Project is "an attempt to show young mathematicians that essentially all of the questions which show up in their undergraduate courses in pure mathematics can be turned into levels of a computer game called Lean". It has published a blog post highlighting very advanced maths, which can now be understood using the interactive theorem prover Lean Johan told us about.
On March 14, the International Day of Mathematics was celebrated worldwide. You can relive the celebration through the live blog, which also includes two video sessions with short talks for a general audience—one with guest mathematicians and one with the 2022 Fields Medal laureates. This year, the community was asked to create Comics. Explore the featured gallery and a map with all of the mathematical comic submissions worldwide.

{kind=link}
Interoperability: Let's play together
In our previous newsletters, we have covered, the Findability and Accessibility principles in FAIR research data. Those are the basic principles that give researchers awareness and access to the existence of research data. In contrast, the remaining two principles, Interoperability and Reusability, are related to what can be done with that data or rather to the quality of it. They have more profound implications for the interactions of the research community as a whole.
Research is almost never conducted in isolation. Researchers build on top of other researchers’ findings, combine different sources with their own insights, and use plenty of tools and methods developed by others. Here we will focus on some technical (and less technical) requirements to make this research community possible: Interoperability.
Interoperability is the capacity to combine pieces from different sources to work together. Standards in science and industry, such as measuring units or the shape of plug connectors, are designed for interoperability. In research, a simple example is language. Most scientific research is nowadays written and published in English. While there may be valid reasons to use other languages (in specific disciplines, in outreach, to foster exchanges in a particular cultural group…), the reality is that using a single lingua franca for scientific research enables comprehension and use of any scientific publication to all researchers. This creates a necessity for researchers to learn and use the English language as part of their research (and life) skills. When it comes to computers, plenty of standards respond to the need for interoperable data, such as file formats or computer languages (pdf, LaTeX, …), some having more success than others.
For research data, interoperability is crucial to enable a research community to collaborate and interact. Interoperability means using a standard set of vocabulary and data models that give a good and agreed representation of the type of research data in question. This effectively sets a standard for data communication. Then each researcher can adapt their tools and methods to process data within those standards.
To be precise, FAIR principles provide a framework for interoperable research data:
- Data and metadata must use a knowledge representation (ontologies, data models) that is shared, broadly applicable, and accessible.
- Such knowledge representation must be itself FAIR.
- When data and metadata reference other data and metadata, their relationship must be qualified (e.g. data X uses algorithm Y in such a way, data Z is derived from dataset W by applying such filtering)
In information science, an ontology is the set of all relevant concepts and relationships for a particular domain. This can be an enumeration or represented by a knowledge graph where nodes are concepts (think of nouns), and edges are qualifiers (think of verbs). This theoretical reflection of the nature of your research data is fundamental to developing useful standards that enable practical interoperability.
The MaRDI project actually devotes a significant part of its efforts to improving the interoperability (and reusability) of research data. Here we provide a brief summary of these interoperability efforts.
Computer Algebra
Computer Algebra concerns calculations on abstract mathematical objects, such as groups, rings, polynomials, manifolds, polytopes, etc. Computations are generally exact (no numerical approximations). Typical use cases of computer algebra are enumeration problems, for instance, finding a list of all graphs with certain properties. For such abstract objects, just data representation is already non-trivial, therefore researchers often build on top of specific frameworks called Computer Algebra Systems (CAS) that implement these data types and methods. Such CASes can be of broad scopes, like Mathematica, Maple, Magma, SageMath, OSCAR, etc, or they can have a focus on a specific domain, like GAP (group theory), Singular (algebraic geometry), Polymake (polytopes and other combinatorial objects), etc. A desirable goal would be to have a common data format to allow interoperability between different software systems without the loss of CAS information, enabling the parsing of files and call of functions from one system to another. This is obviously not an easy task. On the one hand, some of those CASes (e.g. Mathematica, Maple…) are proprietary, their focus is not purely on math research but they also provide tools used in other fields such as engineering or education. Interoperative approaches that use anything other than their provided APIs will therefore likely fail. On the other hand, the specific purpose CASes such as GAP, Singular, or Polymake (incidentally, all three have originated and are maintained by German universities and researchers close to MaRDI) are open-source, and can be used stand-alone but are also integrated into broader CASes such as SageMath (Python based) or OSCAR (Julia based). Turning these specific systems into broad-purpose CASes while also retaining state-of-the-art algorithms from the latest research is already a great success story.
The goals for MaRDI in Computer Algebra are to document and establish workflows, data formats, and guidelines on how to set up databases. By ‘workflows’ we understand this to be the process of generating/retrieving data, setting up an experiment, and obtaining conclusions, which will imply documenting the exact versions of the software (and possibly hardware) used as well as the tech stack (from the operating system to the languages and interpreters and libraries used). This will have benefits such as enabling verification of the results and making further reuse easier. It also provides clear guidelines on which software can be used together, replaced, or mixed, and therefore evaluating its interoperability.
Documenting and establishing data formats means going a step further in the interoperability, not only describing which software or data format the current work adheres to but actually making a system-agnostic description of the data. For instance, if we are using a particular ring of polynomials in several variables with coefficients in a particular field, the data description should make clear how we store and operate the elements of such a ring. Typically, this will follow a data format from a particular CAS, but having an independent description will enable other CASes to implement a compatibility layer to reuse the data. This will become even more relevant when implementing new abstract structures. Eventually, the goal is for all CASes that wish to support a particular data format, to be possible to implement a compatibility layer based on the data description. This is called data serialization, as the goal is to translate internal data structures into a text description, which can be exchanged to another system to be de-serialized, that is, turned into the data structure of the new system with the same semantic information but possibly a different implementation. The MaRDI team is implementing this data serialization in OSCAR, but the goal is to have a system-agnostic specification.
Finally, documenting computer algebra databases will, among other benefits in findability, enable a comprehensive picture of the different systems and the compatibility layers needed to have interoperability amongst them.
Scientific computing
Numerical algorithms are central to scientific computing. Their approximations to exact mathematical quantities come with inherent inexactness and error propagation, due to finite precision in the used data structures. This contrasts with the abstract and exact objects used in Computer Algebra. Typical examples are linear solvers (Ax=b) for different types of matrices (big, small, huge, sparse, dense, stochastic…), or numerical integration methods for ODEs or PDEs. Numerical algorithms are closely associated with applied mathematics, and performance or scalability are relevant factors for choosing one method over another. We already described in the Findability article that MaRDI is building a knowledge graph for those numerical algorithms, together with benchmarks, supporting articles for theoretical background, and other features. But the goal goes beyond creating such a graph just to find algorithms, it is also an ambitious goal to develop an infrastructure to make all these algorithms interoperable.
Researchers implement their algorithms in programming languages such as MATLAB (which is proprietary), or C/C++, Julia, Python, etc, possibly with extension libraries. To implement interoperability between different numerical methods, MaRDI proposes a three-component architecture (driver - connector - implementor). For a particular algorithm, the implementor is the piece of software that contains the actual existing algorithm in whatever language or framework that the author used. The driver is a high-level calling function that contains the semantics of the data, but not the implementation of the algorithm. The same data model can then be used by drivers of different numerical algorithms, even if their implementation uses completely different technologies, thus enabling an interoperable ecosystem. The prototypes of those drivers are being proposed and defined by the MaRDI team. The missing critical piece is the connector, which communicates between the driver and the implementor, which needs to be developed for each algorithm, likely in collaboration with the original author. The MaRDI team is implementing some examples, but the goal is that in the future, any researcher who is developing numerical algorithms can use their preferred technology stack and then easily implement a connector to standard driver functions.
The benchmark comparison between algorithms (planned for the knowledge graph) actually requires this interoperability architecture so that the same test can be executed by different algorithms in equal conditions without a need to adapt the data to fit a particular tech framework.
Statistics and Machine Learning
Typical research data usage in statistics or machine learning include big experimental datasets, frequently coming from other domains. Good examples of this are genetic data or financial data. These datasets contain valuable information that researchers try to extract using statistics or AI techniques. In statistics, for instance, a typical goal is to create a model, meaning to describe a joint probability distribution of all the variables depending on the individual probability distributions of each variable. This means understanding the dependencies between the variables.
A problem often found by statisticians who develop new theoretical methods to extract information from experimental data is that there is only a very limited collection of suitable datasets where they can test new methods. It is difficult to obtain curated data from interdisciplinary teams before the statistical tools are proven useful and robust, which leaves researchers with limited choices to run tests. The most valuable information in curated data includes “ground truths”, that is, relationships between variables that are known externally to the experimental data, via expert knowledge from another field. For instance, in a macroeconomic study, some variables can be related or independent, or their relationship may depend on the presence of a third variable indicator, or even more complex interactions. We may know some of these interactions by knowing government policies or strategies which are not reflected directly in the data. For the statistician, such a "ground truth" is very useful to validate the algorithm used to fit the model. A goal for MaRDI is to collect a broader, curated list of datasets that can be used by statisticians to test and validate modeling techniques. Those datasets need to be cleaned and ready to be used by standard statistical packages (that is, to be interoperable), and to have useful annotated “ground truths” attached to the data for use on interdisciplinary teams. Besides this data collection, MaRDI aims to be a leading example of quality curated data so that experimentalists can adhere to those quality standards.
Another goal concerns machine learning (ML) algorithms. The community around ML is much broader than mathematicians (software developers, data scientists, ML engineers…), and therefore the frameworks used are very diverse. TensorFlow and Torch are two popular tools in the industry, but there are many others. The language R is suitable for statistics and data science, and also for machine learning. An initiative to bring cohesion and interoperability in this software ecosystem is mlr3 (machine learning for the R language), which MaRDI is using and extending. The mlr3 project brings different R packages together (often based on or operating on other frameworks), providing unified naming conventions, and a full suite of tools (learners, benchmarks, analyzers, importers/exporters, …), making R and mlr3 a competitive integrated framework for ML.
We can see a couple of examples of how MaRDI is bridging interoperability gaps in this field. A first example: in machine learning (as in the statistics case we saw earlier), there is a great need for more quality datasets (training, evaluation…). OpenML is a web service that allows sharing of datasets and ML tasks within the ML community. MaRDI is helping to build mlr3oml, an interoperability interface between mlr3 and OpenML. MaRDI also builds and stores “curated quality datasets” in OpenML that can be used for testing and benchmarking, and also as a model of good practices.
A second example: Many learning algorithms in ML are treated as black boxes, they come from different ML techniques and have different implementations. However, a significant part of these algorithms come from some neural network techniques that have some common characteristics: architecture, loss function, optimizer… The package mlr3torch, being developed with MaRDI, aims to “open” some of those black boxes giving greater control of those parameters.
Cooperation with other disciplines
MaRDI strives to bring together mathematical methods and the people who use them. Today this collaboration requires much more than having a common spoken language and publishing in international journals, nowadays data languages are crucial. MaRDI aims to understand and document how researchers in disciplines other than mathematics use (or would like to use) mathematical research data. Hence, the “interoperability” between mathematics and other fields is key. For the past year, MaRDI has collected a series of case studies from other NFDI (the German National Research Data Infrastructure program) consortia, other research groups, and also in the industry, to document through a series of templates how they work and use research data. The key concept is the “workflow”, meaning the documentation of the whole process of setting a theoretical framework, hypothesis to scrutinize, experiment model, data acquisition, technical equipment, metadata association, data processing, software used, data analysis techniques, extraction of results, publications… everything that is directly related to data management, but also its research context. Several examples of workflows can be found on the MaRDI portal TA4 page. Currently, the collected information is textual, highlighting the data acquisition process (and its metadata), and the mathematical model used. In the future, both the (meta)data and the model will be formalized by means of ontologies and model pathway diagrams (graphs) to enable further uses of the research data, such as reproducibility, replacing methods and techniques by newer or more performant ones, or enabling reusability by other researchers.
By looking at the case studies, one can observe that most researchers implement “island solutions” adapted to their specific needs, even if those solutions may be very professional and optimized. There is a great potential to increase interoperability and exchange. MaRDI aims to leverage a change in mathematical data management and analysis to support researchers, in the belief that such a shift will be broadly welcome within the research community.
MaRDI portal
The MaRDI portal will be the single entry point to all the MaRDI services and resources collected by the different task areas. The portal team is currently building a knowledge graph of mathematical research data by retrieving information from other sources (for instance, WikiData, swMATH for documenting mathematical software, package repositories to improve the information granularity of some mathematical software, zbMATH Open to retrieve publications, etc.). This requires a lot of interoperability efforts using the respective APIs since the volume of data is not manageable by hand. Some automation and AI techniques are being considered to foster this process. In due time, all the different MaRDI teams will start producing their output goals, and the portal team will manage the integration within the portal. For instance, the knowledge graph of numerical algorithms will be integrated into the knowledge graph of the MaRDI portal. The statistical datasets collections will also be described as entities in the MaRDI knowledge graph, and so on. In a sense, the portal needs to create interoperability layers between the internal task areas of MaRDI.
All in all, the interoperability principle is an enabling condition for building and strengthening a community. That is the driving goal of all the efforts from MaRDI that we described here. This enabling condition turns into an actual collaboration when the data is reused across different projects and researchers, which will be the topic of our fourth article in this series, about Reusability.




New consortia and an initiative for basic services
On November 4, the Joint Science Conference (GWK) decided to fund seven additional consortia as well as an initiative for the realization of cross-consortia basic services Base4NFDI within the framework of the National Research Data Infrastructure (NFDI). As in the two previous years, the decision by the GWK follows the recommendations of the NFDI expert panel appointed by the German Research Foundation (DFG).
More information:
- in German
International Love Data Week 2023
Love Data Week is an international celebration of data, hosted by the Inter-university Consortium for Political and Social Research (ICPSR), that takes place every year during the week of Valentine's day (in 2023: February 13 - 17). Universities, nonprofit organizations, government agencies, corporations, and individuals around the world are encouraged to host and participate in data-related events and activities held either online or in-person locally. The theme this year is Data: Agent of Change.
More information:
- in English
In October, The Netherlands hosted the "1st international conference on FAIR digital objects" with over 150 professionals signing the Leiden Declaration on FAIR Digital Objects. This is deemed to be "an opportunity for all of us working in research, technology, policy and beyond to support an unprecedented effort to further develop FAIR digital objects, open standards and protocols, and increased reliability and trustworthiness of data".
A group of MaRDI team members together with external experts have written a new article highlighting the status quo, the needs and challenges of research-data management plans for mathematics: a preprint is already available here.
The ICPSR published a guide to data preparation and archiving in 2020. Even though addressed to social scientists, the presented guidelines can be applied to any field.
The "Making MaRDI" Twitter series we announced in the previous Newsletter has been launched and integrated into the website. There are currently four profiles presenting the work that Karsten Tabelow, Tabea Bacher, Christian Himpe, and Ilka Agricola carry out in the consortium.
{kind=link}
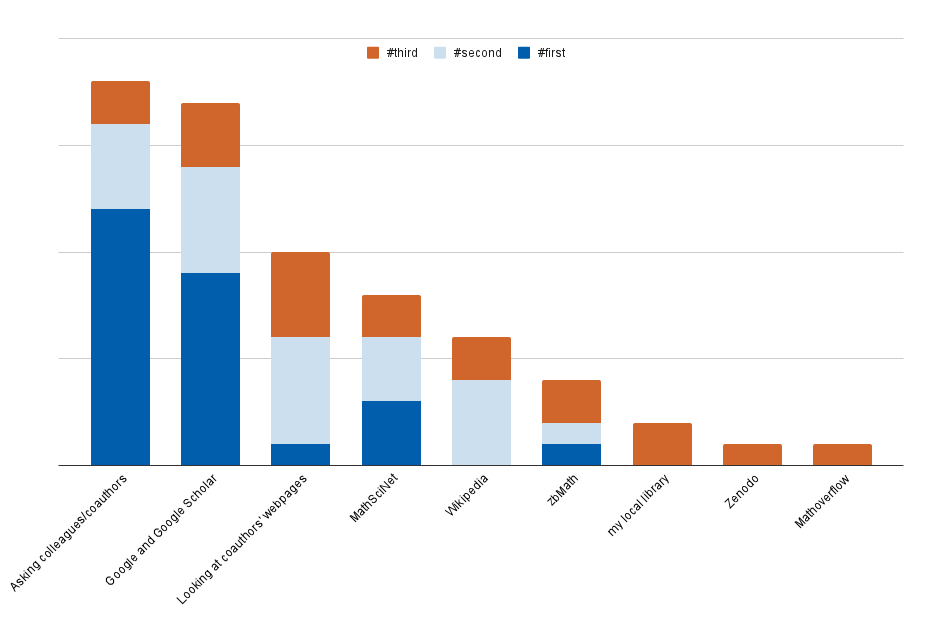

FAIR access to research data
Access to research information is the most fundamental principle for spreading science across the scientific community and society. Publishing and making research results available is a cornerstone of research. This, however, is not exempt from issues. On the one hand, some research is either private, restricted within the industry, or protected by intellectual property. On the other hand, other barriers exist while accessing data in the form of technical incompatibilities, paywalls, bad metadata, or just incomplete data.
The Accessibility principle of FAIR data is the idea that all the relevant data connected to a research result should be properly available. This concerns which data is available, to whom it is accessible, how it is technically stored and retrieved, and how it is classified and managed. This principle is rooted in the scientific fundament of reproducibility and verifiability: other researchers should be able to repeat and independently verify the published results. While this is especially important in the experimental sciences, it also applies to the domain of mathematics.
The FAIR principles state that research data is Accessible when it respects the following recommendations:
- The data is accessible over the internet, possibly after authentication and authorization. The means of access (protocols) must be open, free, and universal, and those protocols must include authentication and authorization whenever necessary.
- The metadata must be available together with the data, and it must persist even after the data is no longer available.
It is important to note the "possibly after authentication and authorization" sentence. It is a common misunderstanding that FAIR accessibility implies free of cost or under open licenses. That is not the case. Free-of-cost publication and open licenses fall into the domain of the Open Access principles. While FAIR and Open Access have points in common, we will see examples where non-open access databases can be FAIR; or open access articles and research data which are not FAIR because metadata or appropriate protocols are missing.
Standards and protocols are a fundamental element in FAIR accessible data. Many tasks, especially those that are repeated in the same way, are performed much more efficiently by machines than by humans. That is why computers are very important when dealing with research data, too. In terms of accessibility, any storage location would ideally provide interfaces where machines can automatically access research data, also referred to as Application Programming Interfaces or APIs.
The research data behind the articles
Let us see three stories of fictional mathematicians that use some research data as a fundamental part of their research. They handle different types of data (databases, classifications, source code, articles...), which can also have different origins (produced by themselves or from a third party). They face different challenges to keep their research data FAIR.
Alice is a mathematician working in computational algebra. She makes intensive use of software, but in her published articles, she often uses sentences such as "using software XX, we can see that...". Her scripts in the form of source code, software packages, toolchains, and her computed results are research data that, if omitted from the published results, are not FAIR data, making her results difficult to be validated or replicated. She is aware of that problem, and she wants to solve that, so she decided to set up a server in her math department with some files with her source code, and she mentions that those files exist on her personal website; maybe she even puts the URL to the code in her articles. However, she has changed from university several times, thus changing her servers and websites, and many files and projects related to older articles are now lost. In order to be fully FAIR compliant, she needs to ensure that the data is bound to a metadata reference and to the research article, that it is accessible through standard internet protocols, and plan for a long-term archive that does not disappear when she changes her job position. Ideally, she would assign a DOI to the source code and host it in some long-time archiving (e.g., Zenodo, GitHub, MathRepo, or others ). Furthermore, she needs to make the code Interoperable and Reusable, which we will discuss in forthcoming issues. The MaRDI project aims to help mathematicians in this situation improve their FAIR data management.
Alice also participates in a collaborative project to classify all instances of her favorite algebraic objects. She and other colleagues have set up an online catalog listing all the known examples, the invariants they use to classify, and bibliographical information. At the moment, this catalog contains a few hundred items; Alice and her team will need to provide download options, filters, and means to retrieve information from the database beyond the graphical web interface. They will need to provide the results in formats that can be further processed with standard tools. That is, they will need an API and standardized formats to allow other researchers to use that database effectively in their own research projects.
Bob and Charlie are mathematicians modelling biological processes. Bob models tumor growth in human cancer, and Charlie neurological activity in animals. They handle three types of data: experimental specimen data in the form of databases that they receive from a partner or third party, model data in the form of source code that they develop, and result data in the form of articles they publish.
For Bob, primary data comes mainly from patients in hospitals. For obvious privacy reasons, Bob cannot directly access that primary data. Instead, he relies on organizations that offer anonymized databases publicly available for research (for example, the National Cancer Institute). Parts of these databases are totally anonymous and can be given open access. Other records contain detailed genetic information that, by their nature, could be used to identify the patient. Those databases have authenticated access, and researchers only can access them after being identified and committing to respect standard good practices in handling medical data. Thus, even if the access is restricted to identified and authenticated people, the data can be FAIR.
For Charlie, keeping his research data FAIR is tricky. He partners with some laboratories that have the appropriate resources to collect data from animals. Since obtaining this experimental data is expensive, the laboratory keeps some rights of use, and Charlie has to sign a "Data Use Agreement" contract. This allows him to use the data only for the declared purpose, and he is unable to redistribute it. In this case, the data would not be FAIR. However, the laboratory agrees to release the data for public use after two or three articles have been published from that source, as they consider that the data has already yielded enough results. From that moment, the data could be considered FAIR. Some websites collect already released databases (e.g., International Brain Lab) or collect data directly from laboratories for researchers' use (e.g., Human Connectome Project).
Bob and Charlie transform the databases they obtain, develop and apply models. They then write and publish articles. It is increasingly common that journals in the modelling field require the source code to be available. Bob and Charlie, like most researchers, use GitHub, but they have other options as we mentioned with Alice. Additionally, interdisciplinary fields with large communities often have collaborative and open-science platforms where many researchers collaborate in large distributed teams (e.g., COMOB, Allen Institute). In those projects, FAIR principles are a basic need. Concerning accessibility, all the data must be perfectly identified by its metadata. Accessibility has to be transparent to the researchers so the source code of their models can retrieve and process the data in a single step. All the platforms mentioned above have high standards of FAIR-ness and offer APIs based on open standards.
Accessibility and Open Access
It is important to distinguish between the "Accessibility" FAIR principle and the "Open Access" practice.
The open-access philosophy states that research data and especially research results (articles) should be available online, free of charge, or from other barriers. This is usually achieved using legal open licenses such as Creative Commons or similar ones.
The open access movement rose in the context of articles and scientific literature by the end of the 90s and the beginning of the 2000s, in the dawn of the internet era. The new technologies (publishing online, print-on-demand, easier distribution...) made the cost of publication lowered dramatically, but at the same time, some editorial houses kept increasing their fees to access scientific journals and started practices such as "bundling" to force libraries to buy subscriptions in bulk. In our academic system, researchers are pressured to publish in prestigious, high-impact journals since their academic valuation highly depends on publication metrics. Most often, journals do not offer remuneration per authoring of scientific articles. Furthermore, researchers often peer-review articles for free, with the incentive of gaining status in their research field. Under those circumstances, the role and the business model of the traditional editorial houses started to be questioned. For several years, discontent grew in the scientific community. Some researchers proposed a boycott (e.g., Tim Gowers against Elsevier), while others defended revolutionary tactics (e.g., Aaron Swartz's Guerrilla Open Access Manifesto) that brought shadow sites to the forefront. These sites offered free and unrestricted access to vast amounts of scientific literature (e.g., Sci-Hub, LibGen) but unauthorized by their copyright holders and thus unlawful in many jurisdictions. In parallel, pre-publication sites such as arXiv that make access to scientific articles free and open have gained much popularity. It is nowadays common to find in arXiv pre-release versions (after peer review and with the final layout) almost identical to the journal-published articles. Other authors directly avoid journals and publish in arXiv (with the consequences it entails, such as loose or lacking review and lack of certifiable merits).
More recently, the open access movement has brought new journals and editorial practices that guarantee access to research articles at no cost. For instance, the Public Library of Science (PLOS) is a non-profit publishing house that advocates for Open Access, releasing all its published articles with Creative Commons licenses. In turn, PLOS brought the practice of pay-to-publish, a scheme that moves the publication fees to the authors or their institutions. While this model is defended by many researchers and publishers, regrettably some deceptive journals exploit this model by charging authors with publication fees without making any quality check or review of the submitted articles. The increasing tendency, however, is to have low-cost journals published only online that can have their small publication costs covered by universities and institutions.
The FAIR principles as described above do not, in essence, interfere with the open access practice, and they do not prescribe open licenses. FAIR is focused on all research data in general, not only articles, and it keeps its recommendations limited to technical aspects such as protocols and APIs and the presence of metadata.
However, the choice of a license for the data does impact the degree of FAIR-ness. While the Findability principle is quite independent of the chosen license, the Accessibility principle is heavily affected by it. Open licenses allow for the redistribution of the data, making access to infrastructure more resilient, durable, and decentralized. It removes barriers and makes use of the right to data more effective. The choice of license has a bigger effect on the principle of reusability in terms of its "legal" and other technical and architectural requirements.
FAIR data and open access are intertwined practices, and researchers need to consider both perspectives, especially in light of developing trends and policies. Recently, the U.S. government issued a memorandum (Ensuring Free, Immediate, and Equitable Access to Federally Funded Research) to all federal agencies establishing immediate access at no cost to all U.S.-funded research. This means that all research paid for with public money must be released in an open format, free of charge. This memorandum includes research data, such as research databases and other primary sources of information. Similar policies can be expected soon in the E.U. countries. Although not yet a binding policy, the European Commission already supports FAIR principles.
MaRDI's proposal concerning Accessibility
The efforts of MaRDI are, on the one hand, geared towards fulfilling the technical needs to have this network of federated repositories: creating APIs and setting standard formats and protocols to access information through the MaRDI portal. On the other hand, MaRDI aims to spread the FAIR culture amongst researchers by providing training on the practices and tools that will improve their data management.
One of the main MaRDI outputs is our portal, which will help researchers to find and access mathematical research data. The portal itself does not create a new gigantic repository to collect all mathematical research data. Instead, it facilitates the creation of a network of federated domain-specific repositories, making the already existing projects more connected, interoperable, and accessible from a single entry point.
In order to enable standardized retrieval of mathematical research data and their metadata, i.e. to make mathematical research data accessible to machines, the MaRDI consortium has decided to set up an API during the five-year funding period (see p.37, 53 of the proposal). This API will be integrated into the MaRDI Portal, the envisioned one-stop contact point for mathematical research data for the scientific community, by FIZ Karlsruhe and Zuse Institute Berlin.
Take as an example, the API of zbMath Open that has similarities to our portal. zbMath Open is a reviewing service for articles in pure and applied mathematics, where you can find 4.4 million bibliographic entries with reviews or abstracts of scholarly literature in mathematics. It has developed an open API offering the bibliographic metadata of each contribution. You can use this in different ways: to provide references for Wikipedia or Mathoverflow, for so-called data-driven decision making, or even for plagiarism detection (see for instance, this article).



NFDI4Culture Music Award
This award, presented in two different categories, is given by the musicological community in NFDI4Culture and it intends to recognize music-related or musicological projects and undertakings. Applications may be submitted by 30. September 2022. The funds (up to 3000 EUR) associated with the award are earmarked for expenses that contribute to the goals of NFDI4Culture and must be used by the end of the year 2023.
More information:
FAIR4Chem Award: The FAIRest dataset in chemistry!
This award is given for published chemistry research datasets that best meet the FAIR principles and thus make a significant contribution to increasing transparency in research and the reuse of scientific knowledge. NFDI4Chem will award the FAIRest dataset with prize money of 500 €, supported by the Fonds der Chemischen Industrie (FCI). Submission deadline is November 15, 2022.
More information:
On the first Monday of every month at 4 pm, the NFDI hosts a live InfraTalk on youtube. Here, participants of the individual consortia talk about important topics to a general audience -- for instance, Harald Sack on Knowledge Graphs (March 7, 2022).
https://www.youtube.com/playlist?list=PL08nwOdK76QlnmEB659qokiWN3AC-kqFS- Danish librarians have set up "How to FAIR: a Danish website to guide researchers on making research data more FAIR" https://doi.org/10.5281/zenodo.3712065. On accessibility, they say "Conducting research is often a team effort. Even before collecting the data, it is important to consider who will get access to the data, under which conditions, and what permissions they will have." and provide lots of use cases from all across the sciences https://www.howtofair.dk/how-to-fair/access-to-data/
FDM Thüringen's Research Data Scarytales promises to "take you on an eerie journey and show you in short stories what scary consequences mistakes in data management can have". The multiple player game comprises of stories based on real events and is designed to avoid potential pitfalls and traps in your Research Data Management plan.


Welcome to the very first issue of the MaRDI (Mathematical Research Data Initiative) Newsletter. Research data in mathematics comes in many different flavors: papers, formulae, theorems, code, scripts, notebooks, software, models, simulated and experimental datasets, libraries of math objects with properties of interest... In short, the list is as long as mathematical research data is diverse.
Unfortunately, there is no straightforward or standard way to make these digital objects available for future generations of researchers. Availability, however, is not the only concern. In an ideal world, mathematical research data would be
FAIR: Findable, Accessible, Interoperable, and Reusable.
MaRDI is a part of the German National Research Data Infrastructure (NFDI) and it is dedicated to building infrastructures to make mathematical research data FAIR. Work on solutions for some of the major problems we face today started last year; from understanding the state-of-the-art technology of a field all the way along the research pipeline to establishing standards for peer review. As part of this process it is especially important for us to engage you, the mathematics community, early on so have a look at the list of our upcoming workshops!
This issue of the Newsletter is dedicated to the F in FAIR: to findability and what this means for mathematics.
{kind=link}

Have you ever…
- tried searching for a formula?
- seen a reference to a homepage that is long gone?
- put code on your personal webpage because you didn't know how and where else to publish it?
- browsed through the publications of your coauthor's coauthors looking for that one result that you almost remembered but not quite?
- not been able to find something you needed to keep going into the research direction you fancied?
Then you are not alone!
To find out, where people search for math data, we ask you to answer our very short multiple-choice survey:
Where do you look for mathematical research data?
You will see the results here or right after submitting your answer.

How to find research data?
In the near-infinite resource aka World Wide Web, where do you find your research data? Where are the concentrating resource “hubs”? How is MaRDI proposing to help on the Findability challenges?
Data and FAIR principles
Modern science, including mathematics, relies increasingly on research data. Research data is the factual material required to verify research findings and in mathematics, this can also be the knowledge written up in an article.
Types of research data would include literature, such as books and articles, databases of experimental data, simulation-generated data, taxonomies (exhaustive listings of the examples of a given category of objects), workflows, and frameworks (for instance software stacks with all the programs used in a research project), etc. Even a single formula could be considered research data. To set up good practices in the scientific community, Wilkinson et al published the FAIR Guiding Principles for scientific data management and stewardship. These principles are Findability, Accessibility, Interoperability, and Reusability.
In this article, we will introduce the Findability principle, with a focus on mathematical sciences, in connection with the infrastructure that is being developed by MaRDI.
For more information about what research data is and how to manage it (especially for researchers in German-speaking countries), you can visit Forschungdaten.info (in German). For a comprehensive introduction to the FAIR principles, you can visit the Go-Fair portal.
Findability
Findability is the first of the FAIR principles; it is also the most basic one because if you can't find some data, you can't re-use it in any way, it is as if it does not exist.
When we try to find (research) data, we may face two situations: either we know that something exists and we are looking for it specifically, or we don't know exactly what we want and we look for anything related to a search term. In the first case, rather than finding that data, our problem is locating it somewhere in the physical or virtual space. In the second, our problem is to examine all the data available (in a certain catalog) for a certain characteristic that we are interested in.
Both problems can be solved by using a few tools. Firstly, each piece of data needs to have a unique reference or identification, so that we can build lookup tables for the location of each dataset. Secondly, together with the ID, we need other metadata that describes the data with some useful information (type, subject, authors, etc). Thirdly, we need to build comprehensive catalogs that gather all the metadata of the datasets and build search engines, which are algorithms to retrieve things from the catalogs.
Thus, the Findability principle can be concretized to the following recommendations:
- (Meta)data is assigned a globally unique and persistent identifier.
- Data is described with rich metadata.
- Metadata clearly and explicitly includes the identifier of the data it describes.
- (Meta)data is registered or indexed in a searchable resource.
The classical approach for searching and finding data has been dominated by the publication paradigm: You look for a specific publication, or for any publication related to a certain topic, that will contain the information you are interested in. However, in reality, you often want to find a theorem, a formula, or any concrete information rather than a publication. For instance a specific expression of a Bessel function, a particular representation of a given group, or the proof that certain differential equations have unique solutions. This approach requires re-thinking how we structure and manage research data. We discuss next the available places to find research data and then the MaRDI proposal for such a comprehensive approach.
Where to look for research data
For mathematical articles, books, and other classically published works, a reference includes title, author, year, etc. While this is easily usable and readable by a human, it is not always consistent in format and it does not provide a means to locate and access that information. The two de-facto standard catalogs that collect mathematical literature and also assign a unique identifier are:
- The ZentralBlatt Mathematik (unique identifier: Zb number), archived in zbMath by the FIZ Karlsruhe - Leibniz Institute and
- The Mathematical Reviews (unique identifier: MR number), archived in MathSciNet by the American Mathematical Society.
While these unique identifiers are helpful in referencing a piece of mathematical literature and these platforms are useful in finding works in a specific math domain, their catalogs are much less comprehensive when it comes to other research data (databases, media, online resources, etc). It also has the drawback that the authors cannot control the existence or the metadata of an entry, and MathSciNet is a subscription-based service*.
Another notable mention is arXiv, which is a de-facto standard platform for pre-publications. Here the actual paper is offered publicly thus making it Accessible. Furthermore, any work in arXiv also gets a unique ID and can be found via the catalog search. The focus here is also on literature, although there is limited support for datasets related to a paper. When it comes to non-literature research data, the panorama is much coarser. swMath, a sister project to zbMath, is a catalog of mathematical software packages (computer algebra, numerics, etc) and a cross-referencing record of their citations articles in zbMath. zbMath also features a full-text search of formulas, which is being improved within the MaRDI framework.
There are also general-purpose identifiers and catalogs for data. One of the most standardized identifiers for online resources is the Digital Object Identifier (DOI), which references any digital object. Unlike a URL, the DOI is linked to a particular file and not to the server or website where it is hosted. The DOI website resolves the DOI number to the most up-to-date URL to access the data, so the DOI also serves as a locator in addition to being a unique identifier. Usually, publishers assign a DOI to new publications but authors can also obtain a DOI in other registration agencies. Some open repositories offer free DOI registration. For instance, Zenodo is a general-purpose repository for open data, which hosts quite a few mathematical research datasets. See our article "Publishing on open repositories" where we talk more about Zenodo.
Currently, for pure research databases (experimental data, simulations data, etc), there is no universally accepted repository in mathematics. There are a few curated collections of mathematical objects, such as the Online Encyclopedia of Integer Sequences (OEIS), the SuiteSparse Matrix Collection, and the NIST Digital Library of Mathematical Functions. The reality is that many researchers rely on open repositories for access to data. Unfortunately, in contrast to biological repositories where researchers can find standardized catalogs of proteins or genetic encodings, mathematical catalogs are neither for general-purpose use nor very interoperable.
MaRDI's proposal concerning Findability
Unfortunately, most data-based mathematical research is still published either without the datasets, or the datasets are hosted on university servers accessible only through personal websites of the researchers involved.
MaRDI aims to, on the one hand, provide the necessary ground infrastructure to properly publish research data in federated repositories (using standards and practices according to the FAIR principles), and on the other, it plans to spread awareness within the math research community on the problems and proposed solutions that publishing research data entails.
Here we will name a few of the initiatives related to the Findability principle.
The Scientific Computing Task Area (TA2) is preparing a benchmark framework to compare existing and new algorithms and methods to solve specific problems. For instance, there are several dozens of methods to solve a linear system Ax=b, with different performance and different technology stacks, depending on the size of the matrix A, if it is sparse or dense, if we look for exact or approximate solutions, etc. So far there is no centralized catalog where a "user" (for instance a computational biologist) can go to choose the best method for their particular application. This catalog and benchmark will make finding symbolic and numerical algorithms much easier and it aspires to be a major reference when looking for such algorithms.
The tool for this is building a knowledge graph of numerical algorithms. A knowledge graph is an abstract representation of a set of concepts, objects, events, or anything related to a domain of study, as nodes, and formal relations between them (edges) that can be read by humans or computers unambiguously. The biggest collective effort to build a knowledge graph is Wikidata. In this mathematical knowledge graph, nodes will be the algorithms themselves as concepts, but also papers related to them, software packages implementing them, benchmarks, and connections to other databases. It will then be possible to navigate the knowledge graph to find semantical information, such as which algorithms extend a given one, where can we find implementations, how do they perform in comparison, etc.
Another effort aimed at Findability in MaRDI is the Mathematical Entity Linking (MathEL), or a way to extract and compare conceptual information from mathematical formulas. The concept of a particular equation (for instance the Klein-Gordon equation, the General Relativity equation, etc) can be expressed in many different forms, variables can be named differently, notations for derivatives or tensors may differ, and groupings and substitutions can occur. The MathEL sub-project aims to retrieve the conceptual information of formulas, propose annotation standards for introducing semantic information into formulas (for instance referencing a WikiData node or other knowledge graph node), to mine large corpora of research data (for instance the Zb catalog or the arXiv repository) and to create user interfaces to retrieve concept and source information, such as question-answering engines.
To illustrate this, here is a sneak peek into the MaRDI portal, under development, which will integrate the MathWebSearch search engine as a MediaWiki component. The formula search can find Wikipages based on formula expressions denoted in LaTeX on the pages on the MaRDI portal. This test wiki page contains a couple of math formulas. This search portal should be able to find those formulas when queried in the search box. With the TeX and BaseX configuration, you can try an input like " V=4/3 \pi r^3 " or " V=\frac{4}{3} \pi r^3 " and it will find the Wiki page with the test formula. Also, with " V = 4/3 \pi ?s^3 " you can find variable substitutions. Other common re-writings are not yet recognized, such as " V = \frac{4\pi}{3} r^3 " but the core search engine is also under active development. The same engine is used in zbMath formulae search. Plans for MaRDI include to make entities in a Wikibase knowledge graph findable through formula search.
In subsequent articles, we will expose other tasks being carried out within MaRDI** that exemplify the other FAIR principles (for instance open interfaces, or descriptions of workflows).
* MR Lookup offers limited services to non-subscribers. As of 2021, ZbMath became zbMATH-open and requires no subscription.
**The funded MaRDI proposal can be accessed here.


Taking some data from a project, we try to prepare it according to the FAIR principles. Follow us in our attempt to make it FAIR on the first try.
Publishing research data in open repositories
We are IMAGINARY, a math communication association, part of the MaRDI consortium and we develop and organize math exhibitions as our main activity. Using data that we collected about Earth grids for one of our recent projects on climate change, we will take you through how we almost painlessly set up data in a public repository.
Our latest exhibition is the "10-minute museum on the climate crisis mathematics", where we describe mathematical modeling and places where maths is used in climate science. We all know that the latitude and longitude grid is the most common way of creating a reference system on the Earth. Did you know there are other ways to divide the Earth into small regions that can be particularly useful in numerical models?




We will also be introducing you to the people who shape MaRDI with their expertise and vision for mathematical research data. They will appear in a series of "Making MaRDI" interviews available via our Twitter account. Stay tuned!

Call for seed funds 2023
These funds support scientists from all fields of research within engineering, relating to the development and implementation of innovative ideas in data management. The grant is equivalent to the funding of a full-time doctoral position for one year. If necessary, the funding can be split between project partners.
More information:
- To learn about the Nationale Forschungsdateninfrastruktur, the community of which MaRDI is just one small part, read the 2021 article by Nathalie Hartl, Elena Wössner, and York Sure-Vetter in Informatik Spektrum. See doi.org/10.1007/s00287-021-01392-6
- Christiane Görgen and Claudia Fevola explain in a short review article the role repositories can play in the MaRDI infrastructure. They use MathRepo as an example, a small math research-data repository hosted at the Max Planck Institute for Mathematics in the Sciences in Leipzig. See arxiv.org/abs/2202.04022
- The interim report of the European Commission Expert Group on FAIR data discusses how to turn FAIR into reality. See doi.org/10.2777/1524
- Thomas Koprucki and Karsten Tabelow have been two of the driving forces in the early stages of MaRDI. Together with Ilka Kleinod they discussed mathematical models as an important type of mathematical research data in a 2016 article for the Proceedings in Applied Mathematics and Mechanics: doi.org/10.1002/pamm.201610458
Our Newsletter "Math & Data Quarterly" is prepared by our partner IMAGINARY. Sign up to get it delivered straight to your inbox quarterly.