{kind=link}

The knowledge ladder
We are not sure exactly how humans store knowledge in their brains, but we certainly pack concepts into units, and then relate those conceptual units together. For example, if asked to list animals, nobody remembers an alphabetical list (unless you explicitly train yourself to remember such a list). Instead, you start the list with something familiar, like a dog, then you recall that dog is a pet animal, and then you list other pet animals like cat or canary. Then you recall that canary is a bird, and then you list other birds, like eagle, falcon, owl… when you run out of birds, you recall that birds fly in the air, which is one environment medium. Another environment medium is water, and this prompts you to start listing fishes and sea animals. This suggests that we can represent human knowledge in the form of a mathematical graph: concepts are nodes, and relationships are edges. This structure is also ingrained in language, which is the way humans communicate and store knowledge. All languages in the world, across all cultures, have nouns, verbs, or adjectives, and establish relationships through sentences. Almost every language organizes sentences in a subject-verb-object pattern (or any permutations: SVO, SOV, VSO, etc). The subject and the object are typically nouns or pronouns, the verb is often a relationship. A sentence like “my mother is a teacher” encodes the following knowledge: the person “my mother” is a node 1, “teacher” is a node 2, and “has as a job” is a relational edge from node 1 to node 2. Also, there is a node 3, the person “me”, and a relationship “is the mother of” from node 1 to node 3, (which implies a reciprocal relationship “is a child of” from node 3 to node 1).
David Somerville / Hugh McLeod
informationversusknowledge-blog.tumblr.com/
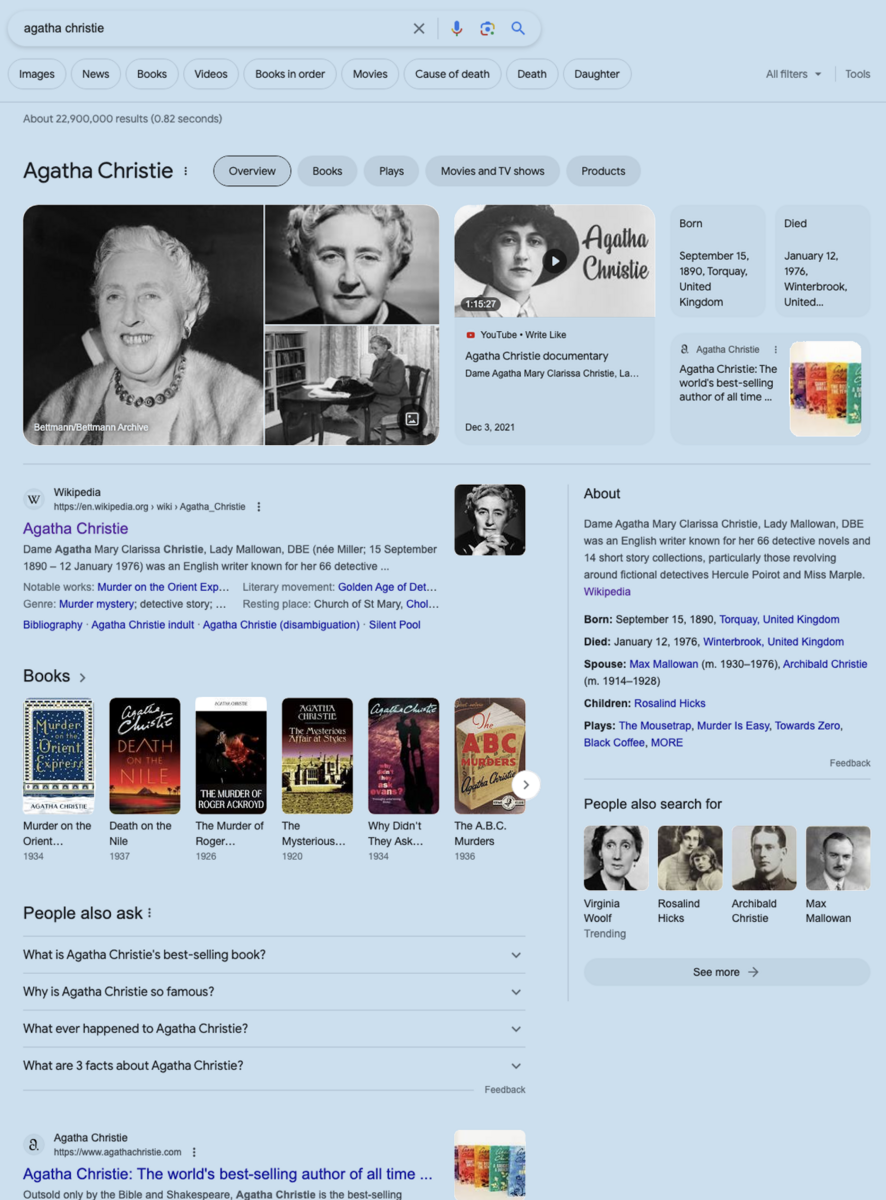
A Google search of “Agatha Christie” in June 2023. It offers much more than just links to webs containing the string “Agatha Christie”. Those boxes “About”, “People also search for”, “People also ask”... are powered by Google’s knowledge graph.
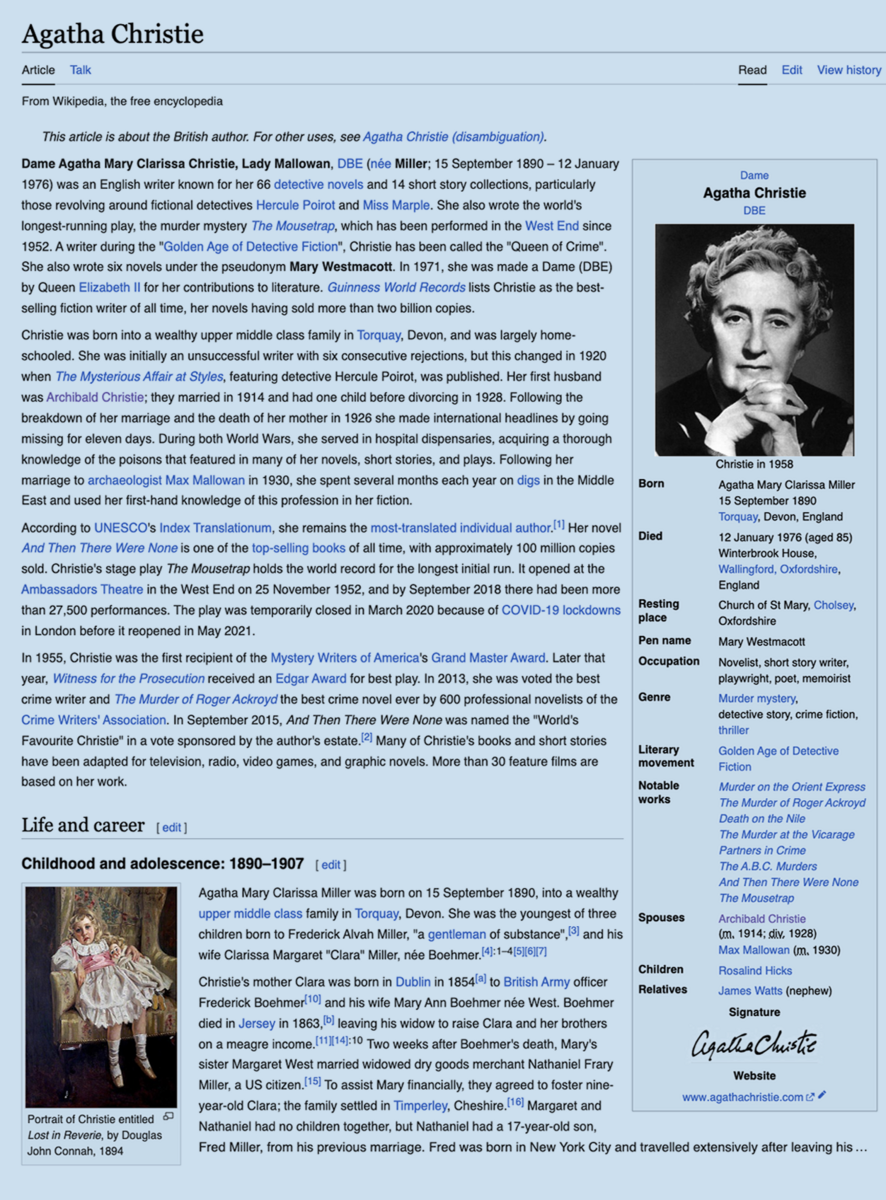
Wikipedia (human-readable, non-structured)
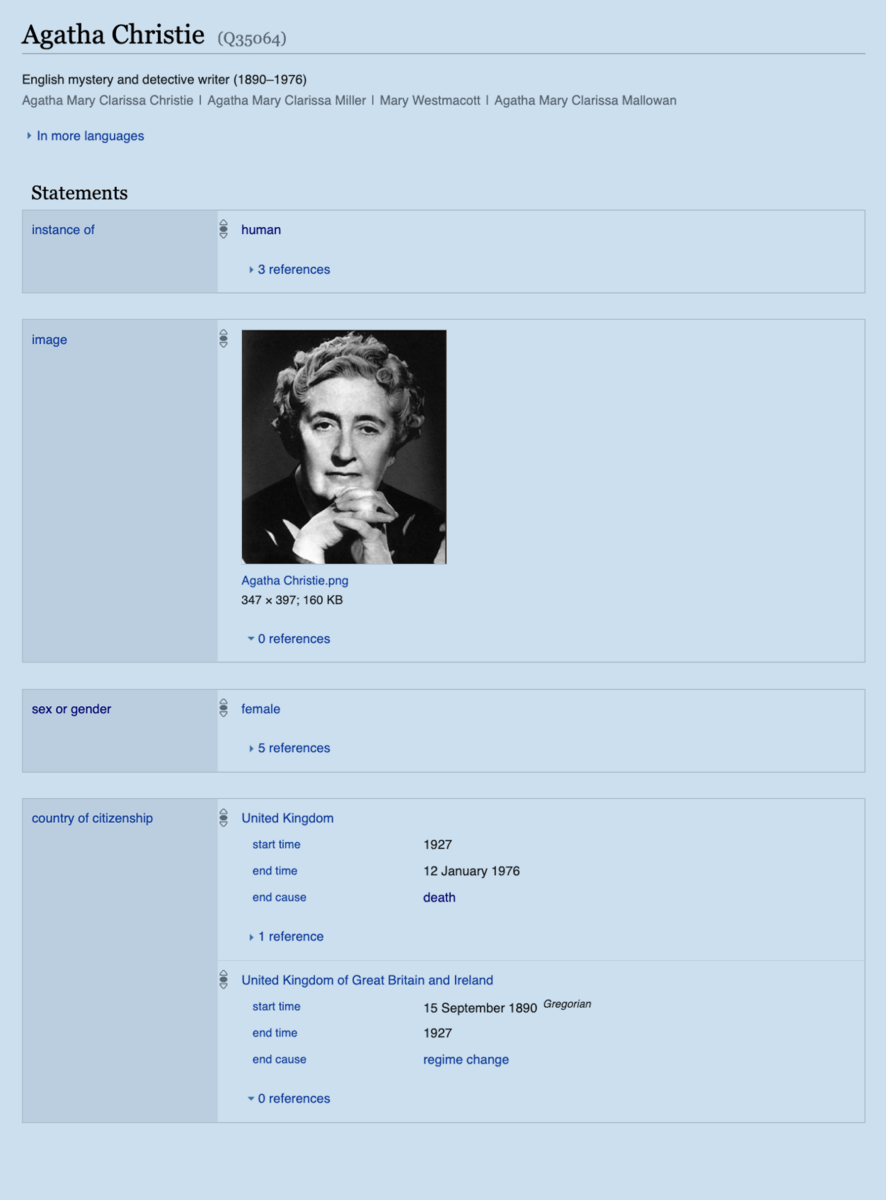
Wikidata (machine-readable, structured)
One of the mottos of MaRDI is “Your Math is Data”. Indeed, from an information theory perspective, all mathematical results (theorems, proofs, formulas, examples, classifications) are data, and some mathematicians also use experimental or computational data (statistical datasets, algorithms, computer code…). MaRDI intends to create the tools, the infrastructure, and the cultural shift to manage and use all research data efficiently. In order to climb up the “knowledge ladder” from Data to Information and Knowledge, the Data needs to be structured, and knowledge graphs are one excellent tool for that goal.
AlgoData
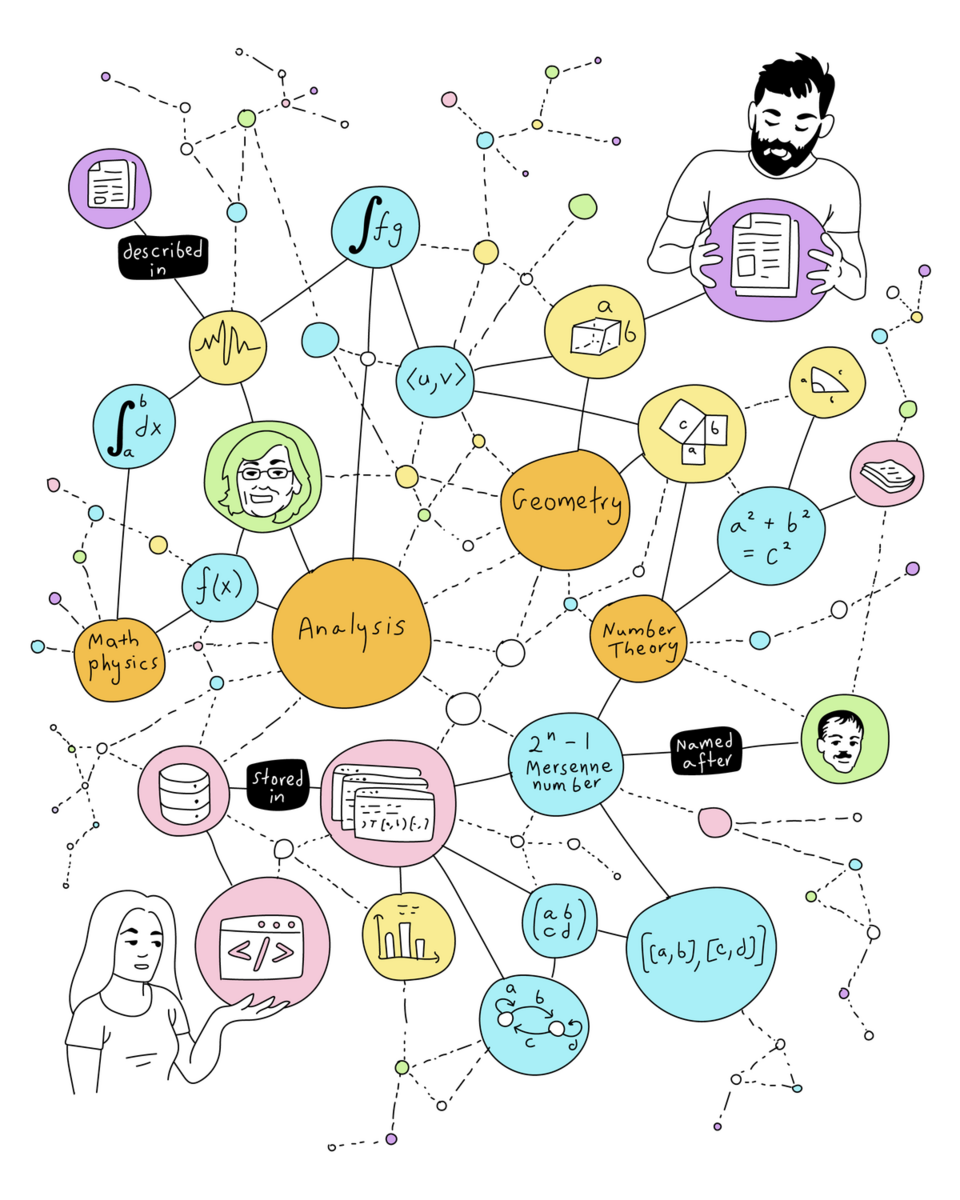
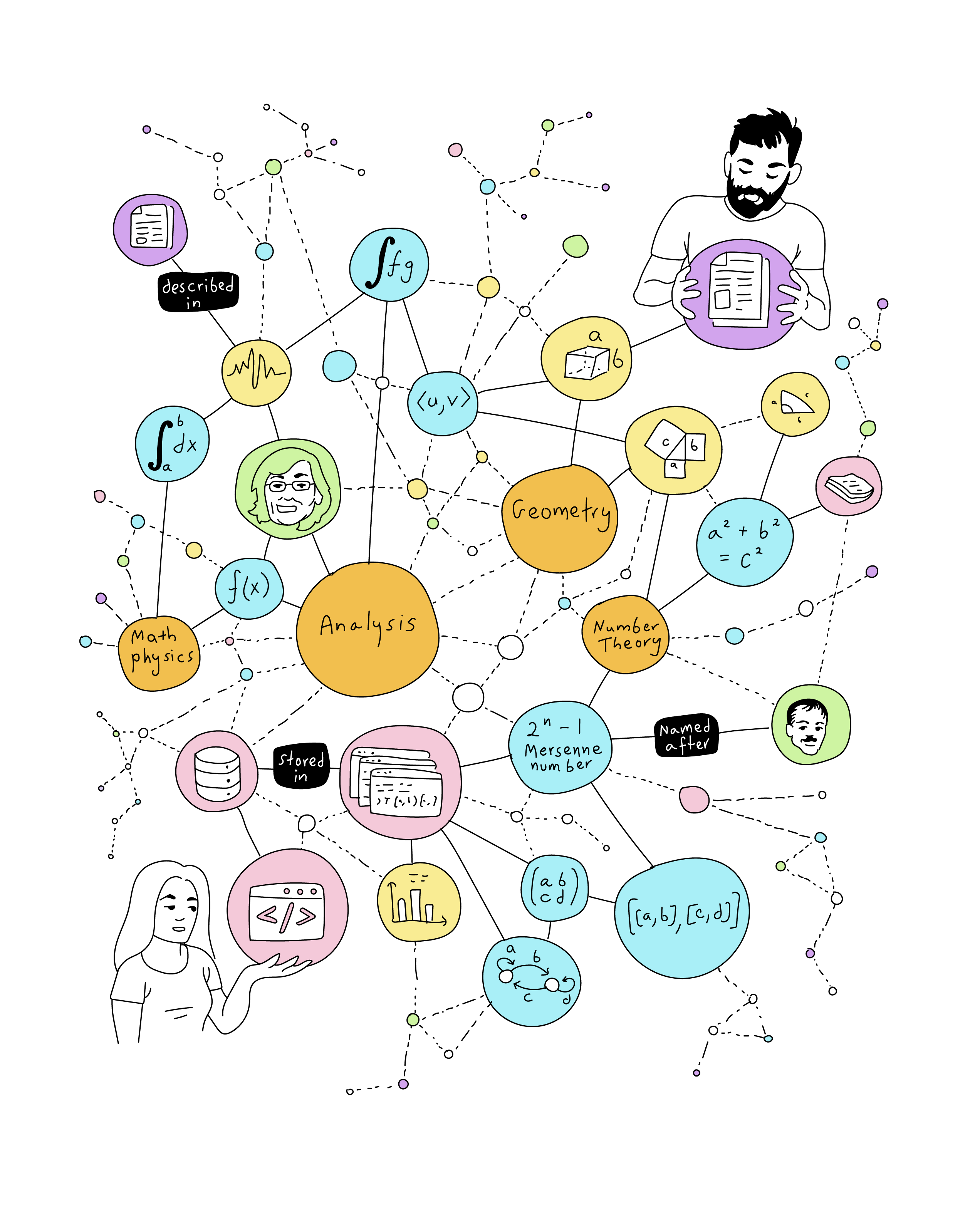
Several initiatives within MaRDI are based on knowledge graphs. A first example is AlgoData (requires MaRDI / ORCID credentials), a knowledge graph of numerical algorithms. In this KG, the main entities (nodes) are algorithms that solve particular problems (such as linear systems of equations or integrate differential equations). Other entities in the graph are supporting information for the algorithms, such as articles, software (code), or benchmarks. For example, we want to encode that algorithm 1 solves problem X, it is described in article Y, it is implemented on software Z, and it scores p points in benchmark W. A use case would be querying for algorithms that solve a particular type of problem, comparing the candidates using certain benchmarks, and retrieving the code to be used (ideally, being interoperable with your system setup).
AlgoData has a well-defined ontology. An ontology (from the Greek, loosely, “study or discourse of the things that exist”) is the set of concepts relevant to your domain. For instance, in an e-commerce site, “article”, “client”, “shopping cart”, or “payment method” are concepts that need to be defined, and included in the implementation of the e-commerce platform. For knowledge graphs, the list would include all types of nodes, and all labels for the edges and other properties. In general-purpose knowledge graphs, such as Wikidata, the ontology is huge, and for practical purposes the user (human or machine) relies on search/suggestion algorithms to identify the property that fits the most to their intention. In contrast, for specific-purpose knowledge graphs, such as AlgoData, a reduced and well-defined ontology is possible, as it simplifies the overall structure and search mechanisms.
The ontology of AlgoData (as of June 2023, under development) is the following:
Classes:
Algorithm, Benchmark, Identifiable, Problem, Publication, Realization, Software.
Object Properties:
analyzes, applies, documents, has component, has subclass, implements, instantiates, invents, is analyzed in, is applied in, is component of, is documented in, is implemented by, is instance of, is invented in, is related to, is solved by, is studied in, is subclass of, is surveyed in, is tested by, is used in, solves, specializedBy, specializes, studies, surveys, tests, uses.
Data Properties:
has category, has identifier.
We can display this ontology as a graph,

The ontology of AlgoData (version 0.1, June 2023)

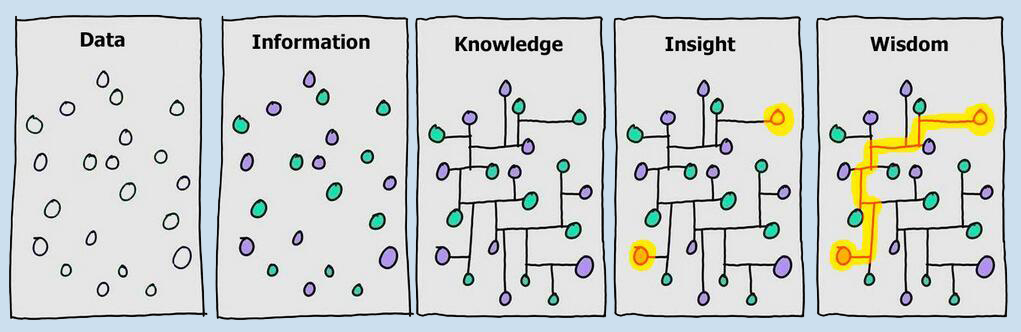
- Knowledge ladder: Steps on which information can be classified, from the rawest to the more structured and useful. Depending on the authors, these steps can be enumerated as Data, Information, Knowledge, Insight, Wisdom.
- Data: raw values collected from measurements.
- Information: Data tagged with its meaning.
- Knowledge: Pieces of information connected together with causal or other relationships.
- Knowledge base: A set of resources (databases, dictionaries…) that represent Knowledge (as in the previous definition).
- Knowledge graph: A knowledge base organized in the form of a mathematical graph.
- Insight: Ability to identify relevant information from a knowledge base.
- Wisdom: Ability to find (or create) connections between information points, using existing or new knowledge relationships.
- Ontology: Set of all the terms and relationships relevant to describe your domain of study. In a knowledge graph, the types of nodes and edges that exist, with all their possible labels.
- RDF (Resource Description Framework): A web standard to describe graphs as triples (subject - predicate - object).
- SPARQL (Simple Protocol And RDF Query Language): A language to send queries (information retrieval/manipulation requests) to graphs in RDF format.
- Wikipedia: a multi-language online encyclopedia based on articles (non-structured human-readable text).
- Wikidata: an all-purpose knowledge graph intended to host data relevant to multiple Wikipedias. As a byproduct, it has become a tool to develop the semantic web, and it acts as a glue between many diverse knowledge graphs.
- Semantic web: a proposed extension of the web in which the content of a website (its meaning, not just the text strings) is machine-readable, to improve search engines and data discovery.
- Mediawiki: the free and open-source software that runs Wikipedia, Wikidata, and also the MaRDI portal and knowledge graph.
- Scholia: A plug-in software for Mediawiki, to enhance visualization of data queries to a knowledge graph
- AlgoData: a knowledge graph for numerical algorithms, part of the MaRDI project.


MaRDI RDM Barcamp
MaRDI, supported by the Bielefeld Center for Data Science (BiCDaS) and the Competence Center for Research Data at Bielefeld University, will host a Barcamp on research-data management in mathematics on July 4th, 2023, at the Center for Interdisciplinary Research (ZiF) in Bielefeld.
More information:
- in English
Working group on Knowledge Graphs
The NFDI working group aims to promote the use of knowledge graphs in all NFDI consortia, to facilitate cross-domain data interlinking and federation following the FAIR principles, and to contribute to the joint development of tools and technologies that enable the transformation of structured and unstructured data into semantically reusable knowledge across different domains. You can sign up to the mailing list of the working group here.
Knowledge graphs in other NFDI consortia can be found for instance at the NFDI4Culture KG (for cultural heritage items) or at the BERD@NFDI KG (for business, economic, and related data items).
More information:
- in English
NFDI-MatWerk Conference
The 1st NFDI-MatWerk Conference to develop a common vision of digital transformation in materials science and engineering will take place from 27 - 29 June 2023 as a hybrid conference. You can still book your ticket for either on-site or online participation (online tickets are even free of charge).
More information:
- in English
Open Science Barcamp
The Barcamp is organized by the Leibniz Strategy Forum Open Science and Wikimedia Deutschland. It is scheduled for 21 September 2023 in Berlin and is open to everybody interested in discussing, learning more about, and sharing experiences on practices in Open Science.
More information:
- in English


- The department of computer science at Stanford University offers this graduate-level research seminar, which includes lectures on knowledge graph topics (e.g., data models, creation, inference, access) and invited lectures from prominent researchers and industry practitioners.
It is available as a 73-page pdf document, divided into chapters:
https://web.stanford.edu/~vinayc/kg/notes/KG_Notes_v1.pdf
and additionally as video playlist:
https://www.youtube.com/playlist?list=PLDhh0lALedc7LC_5wpi5gDnPRnu1GSyRG - Video lecture on knowledge graphs by Prof. Dr. Harald Sack. It covers the topics of basic graph theory, centrality measures, and the importance of a node.
https://www.youtube.com/watch?v=TFT6siFBJkQ The Working Group (WG) Research Ethics of the German Data Forum (RatSWD) has set up the internet portal “Best Practice for Research Ethics”. It bundles information on the topic of research ethics and makes them accessible.
https://www.konsortswd.de/en/ratswd/best-practices-research-ethics/