

"Yesterday at the Math Bazaar exchanging recent research data..."
{kind=link}

Is there Math Data out there?
“Mathematics is the queen and servant of sciences”, according to a quote by Carl F. Gauss. This opinion of Gauss can be a source of philosophical discussions. Is Mathematics even a science? Why does it play a special role? Connecting these questions to our concerns, what is the relationship between research data and these philosophical questions? We cannot arrive at a conclusion in this short article, but it is a good starting point to discuss the mindset (the philosophy, if you wish) that should be adopted regarding research data in mathematical science.
A wide agreement is that a science is any form of study that follows the scientific method: observation, formulation of hypotheses, experimental verification, extraction of conclusions, and back to observation. In most sciences (natural sciences and, to a great extent, also social sciences), observation requires gathering data from nature in the form of empirical records. In contrast, in pure mathematics observations can be made simply by reflection on known theory and logic. In natural sciences, nature is the ultimate judge of the validity or invalidity of a theory. This experimental verification also requires gathering research data in the form of empirical records that support or refute a hypothesis. In contrast, in mathematics, experimental verification is substituted by formal proofs. Such characteristics have prompted some philosophers to claim that mathematics is not really a science, but a meta-science because it does not rely on empirical data. More pragmatically, it can tempt some researchers and mathematicians to say that (at least, pure) mathematics does not use research data. But as you will guess, in the Mathematical Research Data Initiative (MaRDI), we advocate for quite the opposite view.
Firstly, some parts of mathematics do use experimental data extensively. Statistics (and probability) is the branch of mathematics for analyzing large collections of empirical records. Numerical methods are practical tools to perform computations in experimental data. This is the case for pure mathematics as well, where we can build lists of records (prime numbers, polytopes, groups…) that are somewhat experimental.
Secondly, research data are not only empirical records. Data are any raw piece of information upon which we can build knowledge (we discussed the difference between data, information, and knowledge in the previous newsletter). When we talk about research data, we mean any piece of information that researchers can use to build new knowledge in the scientific domain in question, mathematics in this case. As such, articles and books are pieces of data. More precisely, theorems, proofs, formulas, and explanations are individual pieces of data. They have traditionally been bundled into articles and books, and stored in paper, but nowadays are largely available in digital form and accessible through computerized means.
Types of data
In modern mathematical research, we can find many types of data:
Documents (articles, books) and their constituent parts (theorems, proofs, formulas…) are data. Treating mathematical texts as data (and not only as mere containers where one deposits ideas in written form) recognizes that mathematical texts deserve the same treatment as other forms of structured data. In particular, FAIR principles and data management plans also apply to texts.
Literature references are data. Although bibliographic references are part of mathematical documents, we mention them separately because references are structured data. There is a defined set of fields, (such as author, title, publisher…), there are standard formats (e.g. bibTeX), and there are databases of mathematical references (e.g. zbMATH, MathSciNet,...). This makes bibliographic references one of the most curated type of research data (especially in Mathematics) .
Formalized mathematics is data. Languages that implement formal logic like Coq, HOL, Isabelle, Lean, Mizar, etc, are a structured version of the (unstructured) mathematical texts that we just mentioned. They contain proofs verifiable by software and are playing an increasingly vital role in mathematics. Data curation is essential to keep those formalizations useful and bound to their human-readable counterparts.
Software is data. From small scripts that help in a particular problem to wide libraries that integrate into larger frameworks (Sage, Mathematica, MATLAB…). Notebooks (Jupyter,...) are a form of research data that mix text explanations and interactive prompts, so they need to be handled as both documents and software.
Collections of objects are data. Classifications play a major role in mathematics. Either gathered by hand or produced algorithmically, the result can be a pivotal point on which many other works will derive from. Although this output result of a classification can have more applications than the process to arrive at it, it is essential that both input algorithm (or manual process) and the output classification are clearly documented, so that the classification can be verified and reproduced independently, apart from being reused in further projects.
Visualizations and examples are data. Examples and visual realizations of mathematical objects (including images, animations, and other types of graphics) can be very intricate and have an enormous value for understanding and developing a theory. Although examples and visualizations can be omitted in more spartan literature, if provided, they deserve a full research data curation as other research data essential to logical proofs.
Empirical records are data. Of course, raw collection of natural information, intended to be processed to extract knowledge of the data itself, or from the statistical method, are data that need special tools to handle. This applies to statistical databases, but also to machine learning models that require vast amounts of training data.
Simulations are data. Simulations are lists of records not measured from the outside world, but generated from a program. This is usually a representation of a state of a system, including possibly some discretizations and simplifications of reality in the modeling process. As with collections, this output simulation data is as necessary as the input source code that generates it. Simulation data is what allows us to extract conclusions, whereas the reproducibility verification requires that the processing input-to-output be performed by a third party, allowing the recognition of flaws or errors in either the input or the output, or allowing for the rerun of the simulation with different parameters.
Workflow documentations are data. More general than simulations, workflows involve several steps of data acquisition, data processing, data analysis, and extraction of conclusions in many scientific researches. An overview of the process is in itself a valuable piece of data, as it gives insights into the interplay of the different parts. A numerical algorithm can be individually robust and performant, but it may not be the best fit for the task at hand. We can only spot such issues when we have a good overview of the entire process.
The building of mathematics
One key difference between mathematics and other sciences is the existence of proofs. Once a result is proven, it is true forever, as it cannot be overruled by new evidence. The Pythagorean theorem, for instance, is today as valid and useful as it was in the times of Pythagoras (or even in the earlier times of ancient Babylonians and Egyptians, who knew and used it. However, the Greeks invented the concept of proof, turning mathematics from a practice into a science). The Book of Elements by Euclid, written circa 300 BC, one of the most relevant books in the history of mathematics and mankind, perfectly represents the idea that mathematics is a building, or a network, in which each block is built on top of others, in a chain starting with some predetermined axioms. The image shows the dependency graph of propositions in Book I of the Elements.
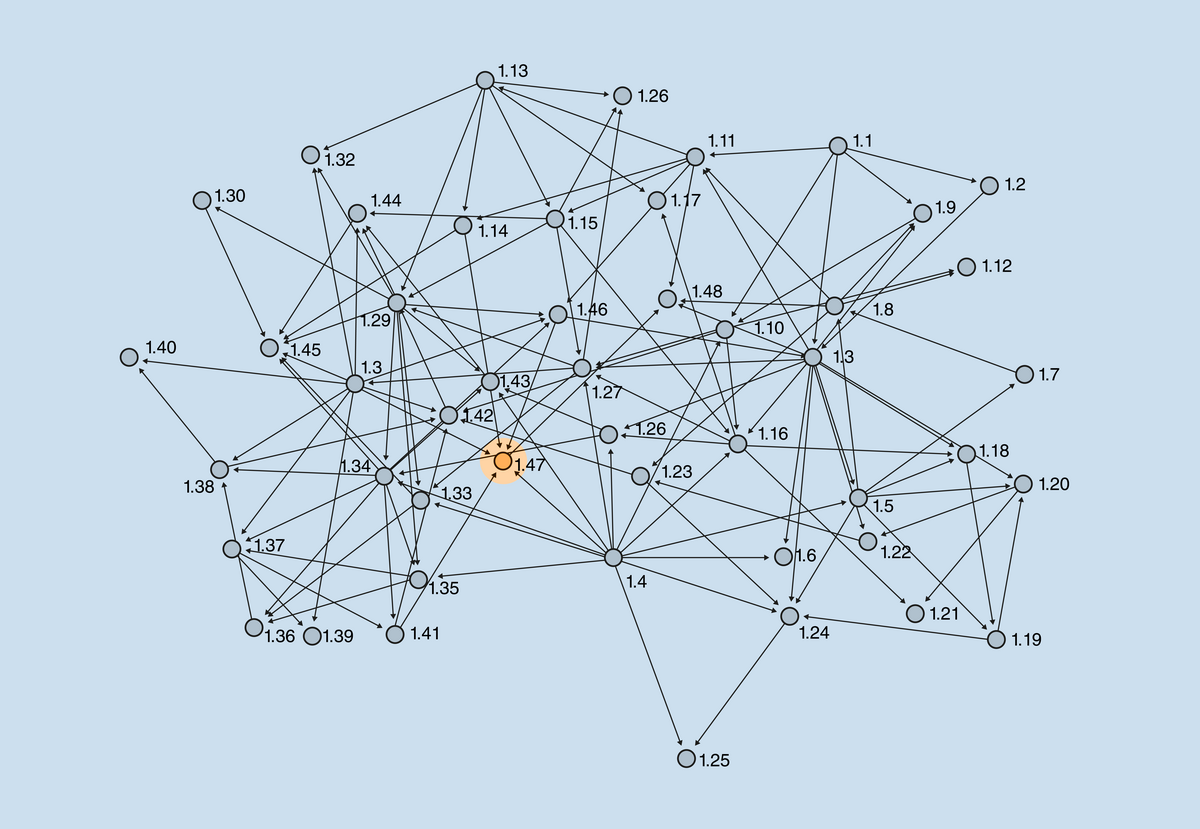
Dependency graph of propositions in Book I of Euclid’s Elements (source). Proposition I.47 is the Pythagorean theorem.




image credit: NFDI-MatWerk

image credit: Heike Fliegl (FIZ)
Math Meets Information Specialists, October 09 - 11, 2023, MPI MiS, Leipzig
MaRDI invites information specialists, librarians, data stewards, and mathematicians to discuss mathematical research data, present their own ideas and services, and make new connections in a three-day noon-to-noon workshop with talks, hands-on sessions, and a barcamp. The workshop will be held in German.
More information:
- in German

Data-Driven Materials Informatics, March 4 - May 24, 2024
The aim of this long program at IMSI is to bring together a diverse scientific audience, both between scientific fields (physical sciences, materials sciences, biophysics, etc.) and within mathematics (mathematical modeling, numerical analysis, statistics, data analysis, etc.), to make progress on key questions of materials informatics.
More information:
- in English
RDM with LinkAhead, September 29, 2023, online
At the NFDI4Chem Stammtisch, the research data management software LinkAhead will be introduced. This agile, open-source software toolbox enables professional data management in research where other approaches are too rigid and inflexible. It will make your data findable and reusable.
More information:

NFDI Code of Conduct
The Consortial assembly, comprising the speakers of each consortium, voted on 27 June 2023 to adopt the code of conduct for the NFDI. This Code of Conduct is intended to provide a binding framework for effective collaboration within the NFDI association.
More information:
- in German


- A a generic JSON based file format which is suitable for computations in computer algebra is described in the paper A FAIR File Format for Mathematical Software by Antony Della Vecchia, Michael Joswig, and Benjamin Lorenz. This file format is implemented in the computer algebra system OSCAR, but the paper also indicates how it can be used in a different context.
- To understand our world, we classify things. A famous example is the periodic table of elements, which describes the properties of all known chemical elements and classifies the building blocks we use in physics, chemistry, and biology. In mathematics, and algebraic geometry in particular, there are many instances of similar periodic tables, describing fundamental classification results. In his article, The Periodic Tables of Algebraic Geometry, Pieter Belmans invites you on a tour of some of these results. It appeared within the series 'Snapshots of modern mathematics from Oberwolfach'.
- Play with the educational tool Classified graphs. With this open-source web app you can draw any graph, or select one from a collection, and then compute a few invariants, such as the adjacency determinant. In the Identify mode, you are challenged to find out which of the graphs in the collection is shown as a target. The tool is part of Pieter Belmans's project Classified maths.
- In each episode of the podcast "Mathematical Objects", Katie Steckles and Peter Rowlett chat about some aspect of mathematics using a mathematical object as inspiration. The podcast is also available on YouTube.
- Proceedings of the Conference on Research Data Infrastructure (CoRDI):
https://www.tib-op.org/ojs/index.php/CoRDI/issue/view/12